
Improving Point-Lookup Using Data Block Hash Index
We’ve designed and implemented a data block hash index in RocksDB that has the benefit of both reducing the CPU util and increasing the throughput for point lookup queries with a reasonable and tunable space overhead.
Specifially, we append a compact hash table to the end of the data block for efficient indexing. It is backward compatible with the data base created without this feature. After turned on the hash index feature, existing data will be gradually converted to the hash index format.
Benchmarks with db_bench show the CPU utilization of one of the main functions in the point lookup code path, DataBlockIter::Seek(), is reduced by 21.8%, and the overall RocksDB throughput is increased by 10% under purely cached workloads, at an overhead of 4.6% more space. Shadow testing with Facebook production traffic shows good CPU improvements too.
How to use it
Two new options are added as part of this feature: BlockBasedTableOptions::data_block_index_type and BlockBasedTableOptions::data_block_hash_table_util_ratio.
The hash index is disabled by default unless BlockBasedTableOptions::data_block_index_type is set to data_block_index_type = kDataBlockBinaryAndHash. The hash table utilization ratio is adjustable using BlockBasedTableOptions::data_block_hash_table_util_ratio, which is valid only if data_block_index_type = kDataBlockBinaryAndHash.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// the definitions can be found in include/rocksdb/table.h
// The index type that will be used for the data block.
enum DataBlockIndexType : char {
kDataBlockBinarySearch = 0, // traditional block type
kDataBlockBinaryAndHash = 1, // additional hash index
};
// Set to kDataBlockBinaryAndHash to enable hash index
DataBlockIndexType data_block_index_type = kDataBlockBinarySearch;
// #entries/#buckets. It is valid only when data_block_hash_index_type is
// kDataBlockBinaryAndHash.
double data_block_hash_table_util_ratio = 0.75;
Data Block Hash Index Design
Current data block format groups adjacent keys together as a restart interval. One block consists of multiple restart intervals. The byte offset of the beginning of each restart interval, i.e. a restart point, is stored in an array called restart interval index or binary seek index. RocksDB does a binary search when performing point lookup for keys in data blocks to find the right restart interval the key may reside. We will use binary seek and binary search interchangeably in this post.
In order to find the right location where the key may reside using binary search, multiple key parsing and comparison are needed. Each binary search branching triggers CPU cache miss, causing much CPU utilization. We have seen that this binary search takes up considerable CPU in production use-cases.
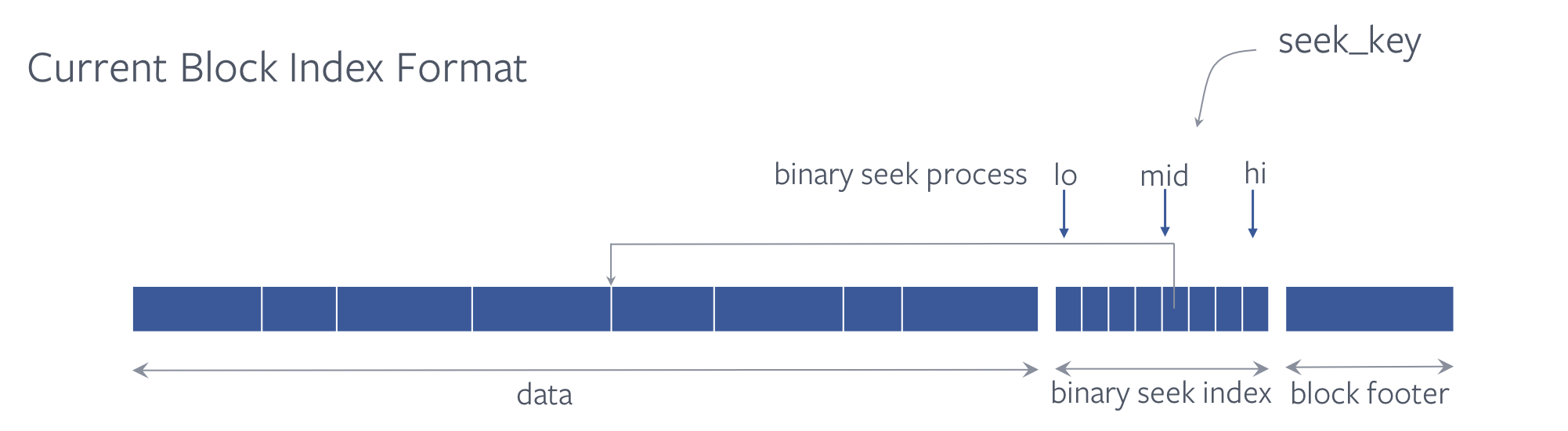
We implemented a hash map at the end of the block to index the key to reduce the CPU overhead of the binary search. The hash index is just an array of pointers pointing into the binary seek index.
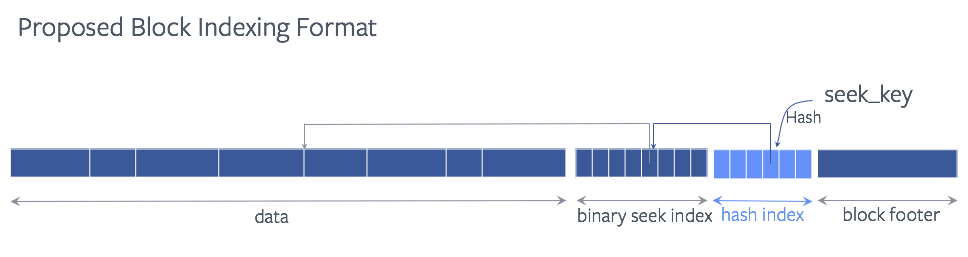
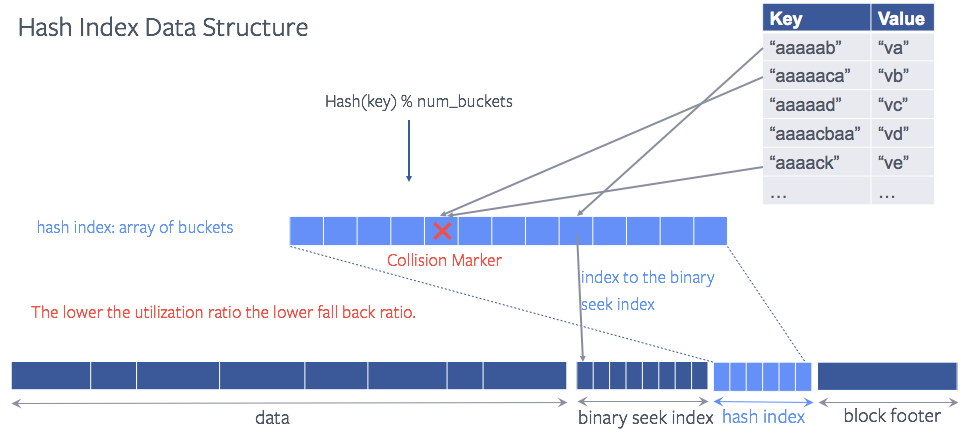
Each array element is considered as a hash bucket when storing the location of a key (or more precisely, the restart index of the restart interval where the key resides). When multiple keys happen to hash into the same bucket (hash collision), we just mark the bucket as “collision”. So that when later querying on that key, the hash table lookup knows that there was a hash collision happened so it can fall back to the traditional binary search to find the location of the key.
We define hash table utilization ratio as the #keys/#buckets. If a utilization ratio is 0.5 and there are 100 buckets, 50 keys are stored in the bucket. The less the util ratio, the less hash collision, and the less chance for a point lookup falls back to binary seek (fall back ratio) due to the collision. So a small util ratio has more benefit to reduce the CPU time but introduces more space overhead.
Space overhead depends on the util ratio. Each bucket is a uint8_t (i.e. one byte). For a util ratio of 1, the space overhead is 1Byte per key, the fall back ratio observed is ~52%.
Things that Need Attention
Customized Comparator
Hash index will hash different keys (keys with different content, or byte sequence) into different hash values. This assumes the comparator will not treat different keys as equal if they have different content.
The default bytewise comparator orders the keys in alphabetical order and works well with hash index, as different keys will never be regarded as equal. However, some specially crafted comparators will do. For example, say, a StringToIntComparator can convert a string into an integer, and use the integer to perform the comparison. Key string “16” and “0x10” is equal to each other as seen by this StringToIntComparator, but they probably hash to different value. Later queries to one form of the key will not be able to find the existing key been stored in the other format.
We add a new function member to the comparator interface:
1
virtual bool CanKeysWithDifferentByteContentsBeEqual() const { return true; }
Every comparator implementation should override this function and specify the behavior of the comparator. If a comparator can regard different keys equal, the function returns true, and as a result the hash index feature will not be enabled, and vice versa.
NOTE: to use the hash index feature, one should 1) have a comparator that can never treat different keys as equal; and 2) override the CanKeysWithDifferentByteContentsBeEqual() function to return false, so the hash index can be enabled.
Util Ratio’s Impact on Data Block Cache
Adding the hash index to the end of the data block essentially takes up the data block cache space, making the effective data block cache size smaller and increasing the data block cache miss ratio. Therefore, a very small util ratio will result in a large data block cache miss ratio, and the extra I/O may drag down the throughput gain achieved by the hash index lookup. Besides, when compression is enabled, cache miss also incurs data block decompression, which is CPU-consuming. Therefore the CPU may even increase if using a too small util ratio. The best util ratio depends on workloads, cache to data ratio, disk bandwidth/latency etc. In our experiment, we found util ratio = 0.5 ~ 1 is a good range to explore that brings both CPU and throughput gains.
Limitations
As we use uint8_t to store binary seek index, i.e. restart interval index, the total number of restart intervals cannot be more than 253 (we reserved 255 and 254 as special flags). For blocks having a larger number of restart intervals, the hash index will not be created and the point lookup will be done by traditional binary seek.
Data block hash index only supports point lookup. We do not support range lookup. Range lookup request will fall back to BinarySeek.
RocksDB supports many types of records, such as Put, Delete, Merge, etc (visit here for more information). Currently we only support Put and Delete, but not Merge. Internally we have a limited set of supported record types:
1
2
3
4
kPutRecord, <=== supported
kDeleteRecord, <=== supported
kSingleDeleteRecord, <=== supported
kTypeBlobIndex, <=== supported
For records not supported, the searching process will fall back to the traditional binary seek.
Evaluation
To evaluate the CPU util reduction and isolate other factors such as disk I/O and block decompression, we first evaluate the hash idnex in a purely cached workload. We observe that the CPU utilization of one of the main functions in the point lookup code path, DataBlockIter::Seek(), is reduced by 21.8% and the overall throughput is increased by 10% at an overhead of 4.6% more space.
However, general worload is not always purely cached. So we also evaluate the performance under different cache space pressure. In the following test, we use db_bench with RocksDB deployed on SSDs. The total DB size is 5~6GB, and it is about 14GB if decompressed. Different block cache sizes are used, ranging from 14GB down to 2GB, with an increasing cache miss ratio.
Orange bars are representing our hash index performance. We use a hash util ratio of 1.0 in this test. Block size are set to 16KiB with the restart interval as 16.
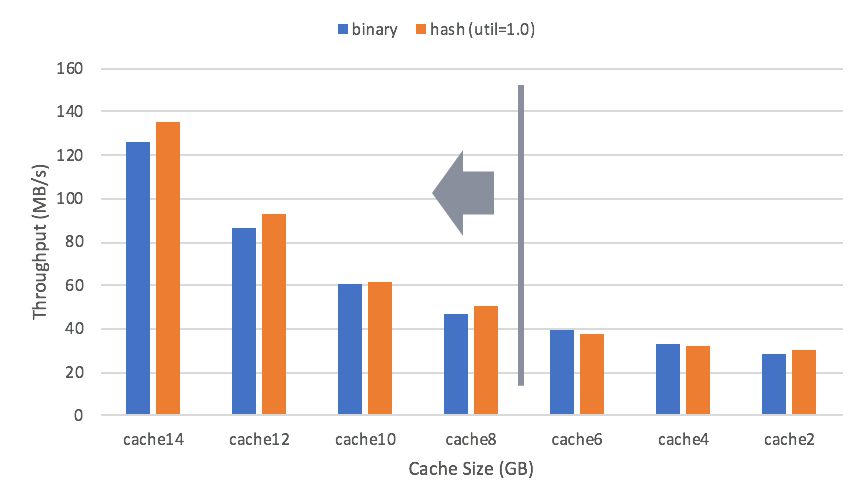
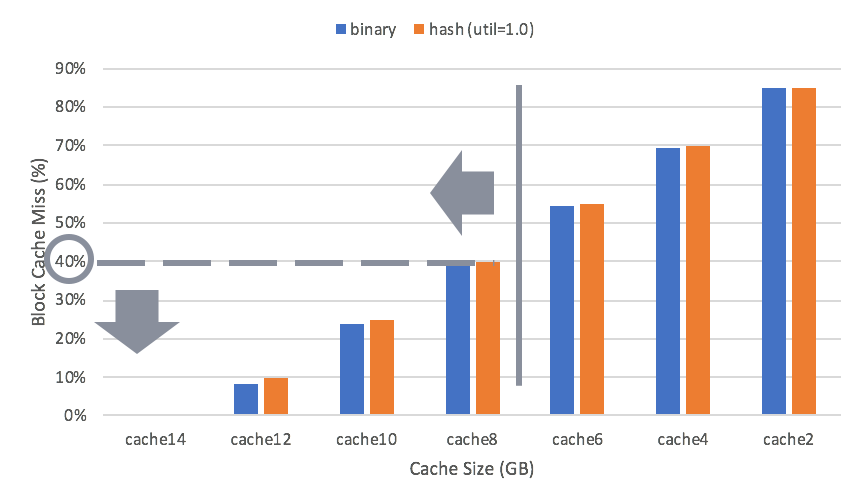
We can see that if cache size is greater than 8GB, hash index can bring throughput gain. Cache size greater than 8GB can be translated to a cache miss ratio smaller than 40%. So if the workload has a cache miss ratio smaller than 40%, hash index is able to increase the throughput.
Besides, shadow testing with Facebook production traffic shows good CPU improvements too.