

DeleteRange: A New Native RocksDB Operation
Motivation
Deletion patterns in LSM
Deleting a range of keys is a common pattern in RocksDB. Most systems built on top of RocksDB have multi-component key schemas, where keys sharing a common prefix are logically related. Here are some examples.
MyRocks is a MySQL fork using RocksDB as its storage engine. Each key’s first four bytes identify the table or index to which that key belongs. Thus dropping a table or index involves deleting all the keys with that prefix.
Rockssandra is a Cassandra variant that uses RocksDB as its storage engine. One
of its admin tool commands, nodetool cleanup, removes key-ranges that have been migrated
to other nodes in the cluster.
Marketplace uses RocksDB to store product data. Its key begins with product ID, and it stores various data associated with the product in separate keys. When a product is removed, all these keys must be deleted.
When we decide what to improve, we try to find a use case that’s common across users, since we want to build a generally useful system, not one that has many one-off features for individual users. The range deletion pattern is common as illustrated above, so from this perspective it’s a good target for optimization.
Existing mechanisms: challenges and opportunities
The most common pattern we see is scan-and-delete, i.e., advance an iterator
through the to-be-deleted range, and issue a Delete for each key. This is
slow (involves read I/O) so cannot be done in any critical path. Additionally,
it creates many tombstones, which slows down iterators and doesn’t offer a deadline
for space reclamation.
Another common pattern is using a custom compaction filter that drops keys in the deleted range(s). This deletes the range asynchronously, so cannot be used in cases where readers must not see keys in deleted ranges. Further, it has the disadvantage of outputting tombstones to all but the bottom level. That’s because compaction cannot detect whether dropping a key would cause an older version at a lower level to reappear.
If space reclamation time is important, or it is important that the deleted
range not affect iterators, the user can trigger CompactRange on the deleted
range. This can involve arbitrarily long waits in the compaction queue, and
increases write-amp. By the time it’s finished, however, the range is completely
gone from the LSM.
DeleteFilesInRange can be used prior to compacting the deleted range as long
as snapshot readers do not need to access them. It drops files that are
completely contained in the deleted range. That saves write-amp because, in
CompactRange, the file data would have to be rewritten several times before it
reaches the bottom of the LSM, where tombstones can finally be dropped.
In addition to the above approaches having various drawbacks, they are quite complicated to reason about and implement. In an ideal world, deleting a range of keys would be (1) simple, i.e., a single API call; (2) synchronous, i.e., when the call finishes, the keys are guaranteed to be wiped from the DB; (3) low latency so it can be used in critical paths; and (4) a first-class operation with all the guarantees of any other write, like atomicity, crash-recovery, etc.
v1: Getting it to work
Where to persist them?
The first place we thought about storing them is inline with the data blocks. We could not think of a good way to do it, however, since the start of a range tombstone covering a key could be anywhere, making binary search impossible. So, we decided to investigate segregated storage.
A second solution we considered is appending to the manifest. This file is append-only, periodically compacted, and stores metadata like the level to which each SST belongs. This is tempting because it leverages an existing file, which is maintained in the background and fully read when the DB is opened. However, it conceptually violates the manifest’s purpose, which is to store metadata. It also has no way to detect when a range tombstone no longer covers anything and is droppable. Further, it’d be possible for keys above a range tombstone to disappear when they have their seqnums zeroed upon compaction to the bottommost level.
A third candidate is using a separate column family. This has similar problems to the manifest approach. That is, we cannot easily detect when a range tombstone is obsolete, and seqnum zeroing can cause a key to go from above a range tombstone to below, i.e., disappearing. The upside is we can reuse logic for memory buffering, consistent reads/writes, etc.
The problems with the second and third solutions indicate a need for range tombstones to be aware of flush/compaction. An easy way to achieve this is put them in the SST files themselves - but not in the data blocks, as explained for the first solution. So, we introduced a separate meta-block for range tombstones. This resolved the problem of when to obsolete range tombstones, as it’s simple: when they’re compacted to the bottom level. We also reused the LSM invariants that newer versions of a key are always in a higher level to prevent the seqnum zeroing problem. This approach has the side benefit of constraining the range tombstones seen during reads to ones in a similar key-range.
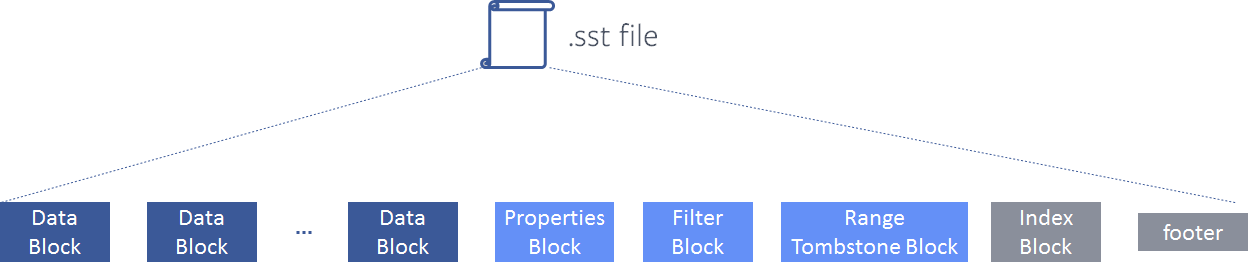
When there are range tombstones in an SST, they are segregated in a separate meta-block
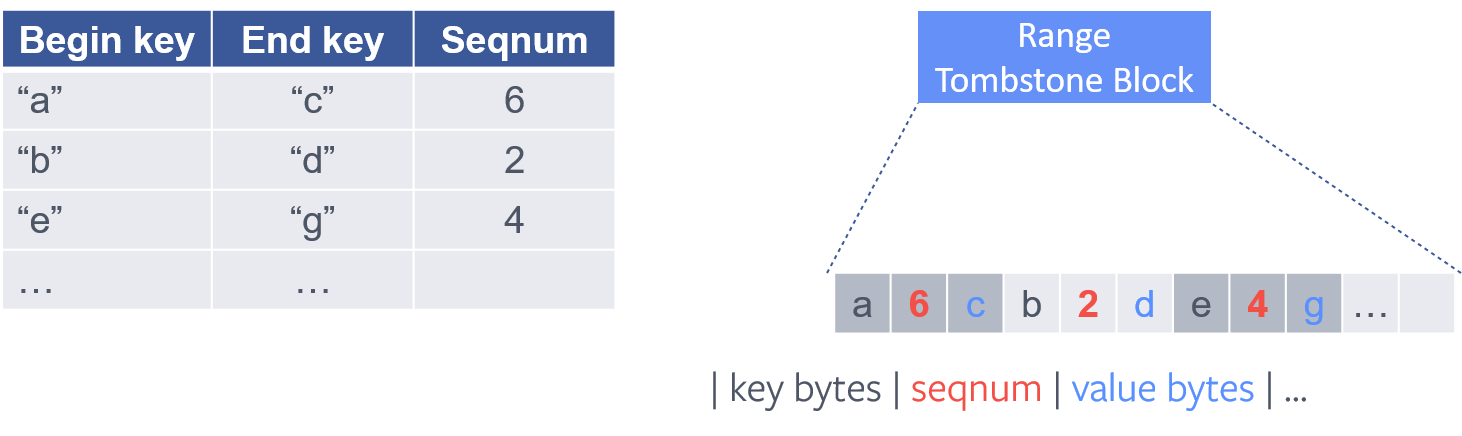
Logical range tombstones (left) and their corresponding physical key-value representation (right)
Write path
WriteBatch stores range tombstones in its buffer which are logged to the WAL and
then applied to a dedicated range tombstone memtable during Write. Later in
the background the range tombstone memtable and its corresponding data memtable
are flushed together into a single SST with a range tombstone meta-block. SSTs
periodically undergo compaction which rewrites SSTs with point data and range
tombstones dropped or merged wherever possible.
We chose to use a dedicated memtable for range tombstones. The memtable representation is always skiplist in order to minimize overhead in the usual case, which is the memtable contains zero or a small number of range tombstones. The range tombstones are segregated to a separate memtable for the same reason we segregated range tombstones in SSTs. That is, we did not know how to interleave the range tombstone with point data in a way that we would be able to find it for arbitrary keys that it covers.
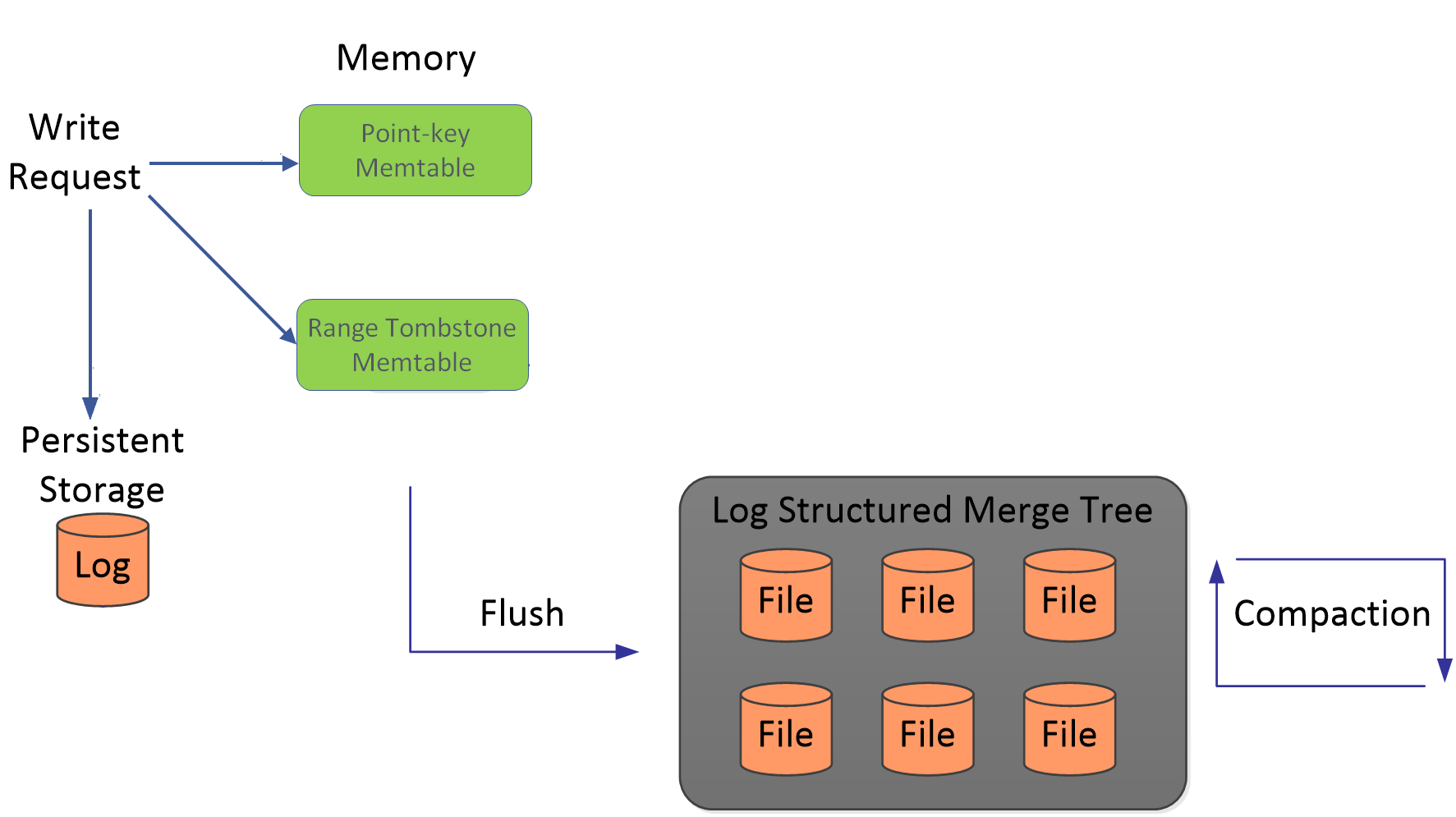
Lifetime of point keys and range tombstones in RocksDB
During flush and compaction, we chose to write out all non-obsolete range tombstones unsorted. Sorting by a single dimension is easy to implement, but doesn’t bring asymptotic improvement to queries over range data. Ideally, we want to store skylines (see “Read Path” subsection below) computed over our ranges so we can binary search. However, a couple of concerns cause doing this in flush and compaction to feel unsatisfactory: (1) we need to store multiple skylines, one for each snapshot, which further complicates the range tombstone meta-block encoding; and (2) even if we implement this, the range tombstone memtable still needs to be linearly scanned. Given these concerns we decided to defer collapsing work to the read side, hoping a good caching strategy could optimize this at some future point.
Read path
In point lookups, we aggregate range tombstones in an unordered vector as we search through live memtable, immutable memtables, and then SSTs. When a key is found that matches the lookup key, we do a scan through the vector, checking whether the key is deleted.
In iterators, we aggregate range tombstones into a skyline as we visit live
memtable, immutable memtables, and SSTs. The skyline is expensive to construct but fast to determine whether a key is covered. The skyline keeps track of the most recent range tombstone found to optimize Next and Prev.
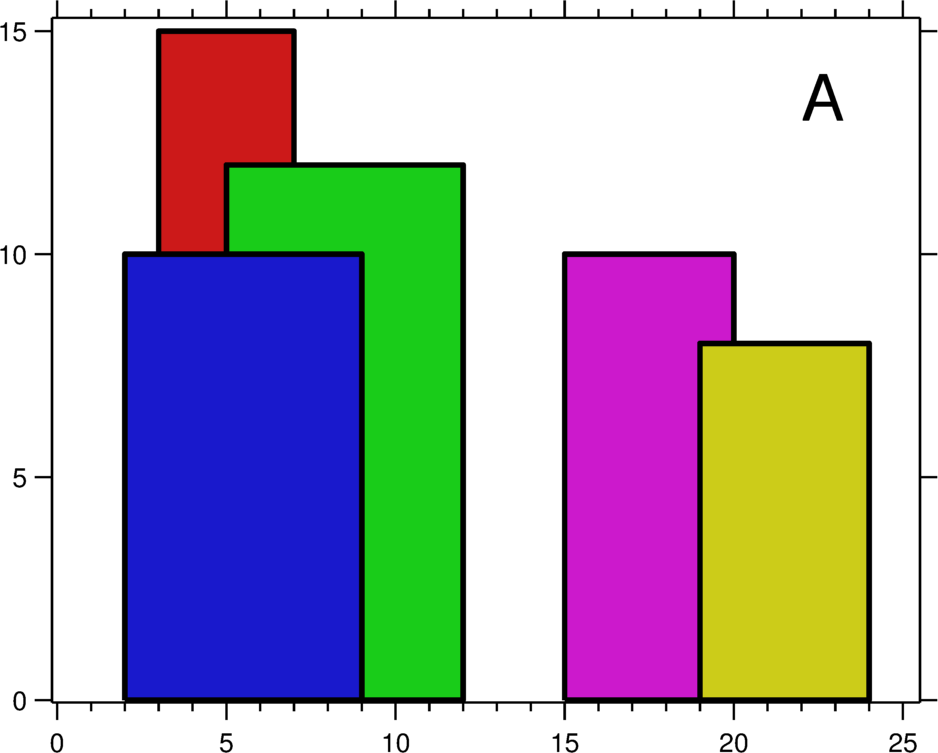 |
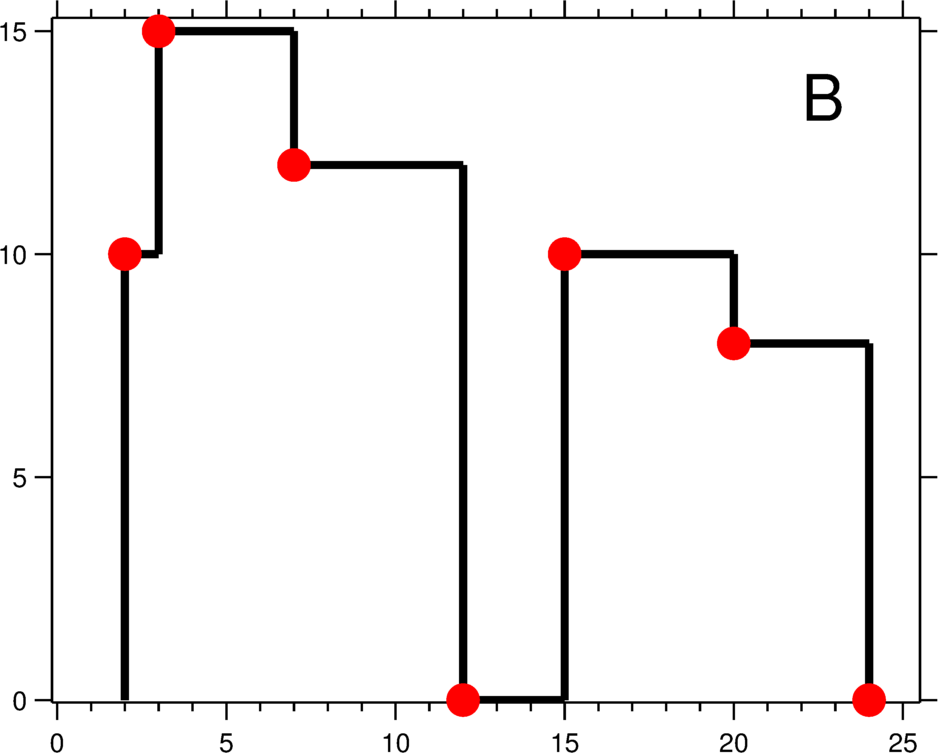 |
(Image source: Leetcode) The skyline problem involves taking building location/height data in the unsearchable form of A and converting it to the form of B, which is binary-searchable. With overlapping range tombstones, to achieve efficient searching we need to solve an analogous problem, where the x-axis is the key-space and the y-axis is the sequence number.
Performance characteristics
For the v1 implementation, writes are much faster compared to the scan and
delete (optionally within a transaction) pattern. DeleteRange only logs to WAL
and applies to memtable. Logging to WAL always fflushes, and optionally
fsyncs or fdatasyncs. Applying to memtable is always an in-memory operation.
Since range tombstones have a dedicated skiplist memtable, the complexity of inserting is O(log(T)), where T is the number of existing buffered range tombstones.
Reading in the presence of v1 range tombstones, however, is much slower than reads in a database where scan-and-delete has happened, due to the linear scan over range tombstone memtables/meta-blocks.
Iterating in a database with v1 range tombstones is usually slower than in a scan-and-delete database, although the gap lessens as iterations grow longer. When an iterator is first created and seeked, we construct a skyline over its tombstones. This operation is O(T*log(T)) where T is the number of tombstones found across live memtable, immutable memtable, L0 files, and one file from each of the L1+ levels. However, moving the iterator forwards or backwards is simply a constant-time operation (excluding edge cases, e.g., many range tombstones between consecutive point keys).
v2: Making it fast
DeleteRange’s negative impact on read perf is a barrier to its adoption. The
root cause is range tombstones are not stored or cached in a format that can be
efficiently searched. We needed to design DeleteRange so that we could maintain
write performance while making read performance competitive with workarounds
used in production (e.g., scan-and-delete).
Representations
The key idea of the redesign is that, instead of globally collapsing range tombstones, we can locally “fragment” them for each SST file and memtable to guarantee that:
- no range tombstones overlap; and
- range tombstones are ordered by start key.
Combined, these properties make range tombstones binary searchable. This fragmentation will happen on the read path, but unlike the previous design, we can easily cache many of these range tombstone fragments on the read path.
Write path
The write path remains unchanged.
Read path
When an SST file is opened, its range tombstones are fragmented and cached. For point lookups, we binary search each file’s fragmented range tombstones for one that covers the lookup key. Unlike the old design, once we find a tombstone, we no longer need to search for the key in lower levels, since we know that any keys on those levels will be covered (though we do still check the current level since there may be keys written after the range tombstone).
For range scans, we create iterators over all the fragmented range tombstones and store them in a list, seeking each one to cover the start key of the range scan (if possible), and query each encountered key in this structure as in the old design, advancing range tombstone iterators as necessary. In effect, we implicitly create a skyline. This requires significantly less work on iterator creation, but since each memtable/SST has its own range tombstone iterator, querying range tombstones requires key comparisons (and possibly iterator increments) for several iterators (as opposed to v1, where we had a global collapsed representation of all range tombstones). As a result, very long range scans may become slower than before, but short range scans are an order of magnitude faster, which are the more common class of range scan.
Benchmarks
To understand the performance of this new design, we used db_bench to compare point lookup, short range scan,
and long range scan performance across:
- the v1 DeleteRange design,
- the scan-and-delete workaround, and
- the v2 DeleteRange design.
In these benchmarks, we used a database with 5 million data keys, and 10000 range tombstones (ignoring those dropped during compaction) that were written in regular intervals after 4.5 million data keys were written. Writing the range tombstones ensures that most of them are not compacted away, and we have more tombstones in higher levels that cover keys in lower levels, which allows the benchmarks to exercise more interesting behavior when reading deleted keys.
Point lookup benchmarks read 100000 keys from a database using readwhilewriting. Range scan benchmarks used
seekrandomwhilewriting and seeked 100000 times, and advanced up to 10 keys away from the seek position for short range scans, and advanced up to 1000 keys away from the seek position for long range scans.
The results are summarized in the tables below, averaged over 10 runs (note the
different SHAs for v1 benchmarks are due to a new db_bench flag that was added in order to compare performance with databases with no tombstones; for brevity, those results are not reported here). Also note that the block cache was large enough to hold the entire db, so the large throughput is due to limited I/Os and little time spent on decompression. The range tombstone blocks are always pinned uncompressed in memory. We believe these setup details should not affect relative performance between versions.
Point Lookups
| Name | SHA | avg micros/op | avg ops/sec |
| v1 | 35cd754a6 | 1.3179 | 759,830.90 |
| scan-del | 7528130e3 | 0.6036 | 1,667,237.70 |
| v2 | 7528130e3 | 0.6128 | 1,634,633.40 |
Short Range Scans
| Name | SHA | avg micros/op | avg ops/sec |
| v1 | 0ed738fdd | 6.23 | 176,562.00 |
| scan-del | PR 4677 | 2.6844 | 377,313.00 |
| v2 | PR 4677 | 2.8226 | 361,249.70 |
Long Range scans
| Name | SHA | avg micros/op | avg ops/sec |
| v1 | 0ed738fdd | 52.7066 | 19,074.00 |
| scan-del | PR 4677 | 38.0325 | 26,648.60 |
| v2 | PR 4677 | 41.2882 | 24,714.70 |
Future Work
Note that memtable range tombstones are fragmented every read; for now this is acceptable, since we expect there to be relatively few range tombstones in memtables (and users can enforce this by keeping track of the number of memtable range deletions and manually flushing after it passes a threshold). In the future, a specialized data structure can be used for storing range tombstones in memory to avoid this work.
Another future optimization is to create a new format version that requires range tombstones to
be stored in a fragmented form. This would save time when opening SST files, and when max_open_files
is not -1 (i.e., files may be opened several times).
Acknowledgements
Special thanks to Peter Mattis and Nikhil Benesch from Cockroach Labs, who were early users of DeleteRange v1 in production, contributed the cleanest/most efficient v1 aggregation implementation, found and fixed bugs, and provided initial DeleteRange v2 design and continued help.
Thanks to Huachao Huang and Jinpeng Zhang from PingCAP for early DeleteRange v1 adoption, bug reports, and fixes.