
Preset Dictionary Compression
Summary
Compression algorithms relying on an adaptive dictionary, such as LZ4, zstd, and zlib, struggle to achieve good compression ratios on small inputs when using the basic compress API. With the basic compress API, the compressor starts with an empty dictionary. With small inputs, not much content gets added to the dictionary during the compression. Combined, these factors suggest the dictionary will never have enough contents to achieve great compression ratios.
RocksDB groups key-value pairs into data blocks before storing them in files. For use cases that are heavy on random accesses, smaller data block size is sometimes desirable for reducing I/O and CPU spent reading blocks. However, as explained above, smaller data block size comes with the downside of worse compression ratio when using the basic compress API.
Fortunately, zstd and other libraries offer advanced compress APIs that preset the dictionary. A preset dictionary makes it possible for the compressor to start from a useful state instead of from an empty one, making compression immediately effective.
RocksDB now optionally takes advantage of these dictionary presetting APIs. The challenges in integrating this feature into the storage engine were more substantial than apparent on the surface. First, we need to target a preset dictionary to the relevant data. Second, preset dictionaries need to be trained from data samples, which need to be gathered. Third, preset dictionaries need to be persisted since they are needed at decompression time. Fourth, overhead in accessing the preset dictionary must be minimized to prevent regression in critical code paths. Fifth, we need easy-to-use measurement to evaluate candidate use cases and production impact.
In production, we have deployed dictionary presetting to save space in multiple RocksDB use cases with data block size 8KB or smaller. We have measured meaningful benefit to compression ratio in use cases with data block size up to 16KB. We have also measured a use case that can save both CPU and space by reducing data block size and turning on dictionary presetting at the same time.
Feature design
Targeting
Over time we have considered a few possibilities for the scope of a dictionary.
- Subcompaction
- SST file
- Column family
The original choice was subcompaction scope. This enabled an approach with minimal buffering overhead because we could collect samples while generating the first output SST file. The dictionary could then be trained and applied to subsequent SST files in the same subcompaction.
However, we found a large use case where the proximity of data in the keyspace was more correlated with its similarity than we had predicted. In particular, the approach of training a dictionary on an adjacent file yielded substantially worse ratios than training the dictionary on the same file it would be used to compress. In response to this finding, we changed the preset dictionary scope to per SST file.
With this change in approach, we had to face the problem we had hoped to avoid: how can we compress all of an SST file’s data blocks with the same preset dictionary while that dictionary can only be trained after many data blocks have been sampled? The solutions we considered both involved a new overhead. We could read the input more than once and introduce I/O overhead, or we could buffer the uncompressed output file data blocks until a dictionary is trained, introducing memory overhead. We chose to take the hit on memory overhead.
Another approach that we considered was associating multiple dictionaries with a column family. For example, in MyRocks there could be a dictionary trained on data from each large table. When compressing a data block, we would look at the table to which its data belongs and pick the corresponding dictionary. However, this approach would introduce many challenges. RocksDB would need to be aware of the key schema to know where are the table boundaries. RocksDB would also need to periodically update the dictionaries to account for changes in data pattern. It would need somewhere to store dictionaries at column family scope. Overall, we thought these challenges were too difficult to pursue the approach.
Training
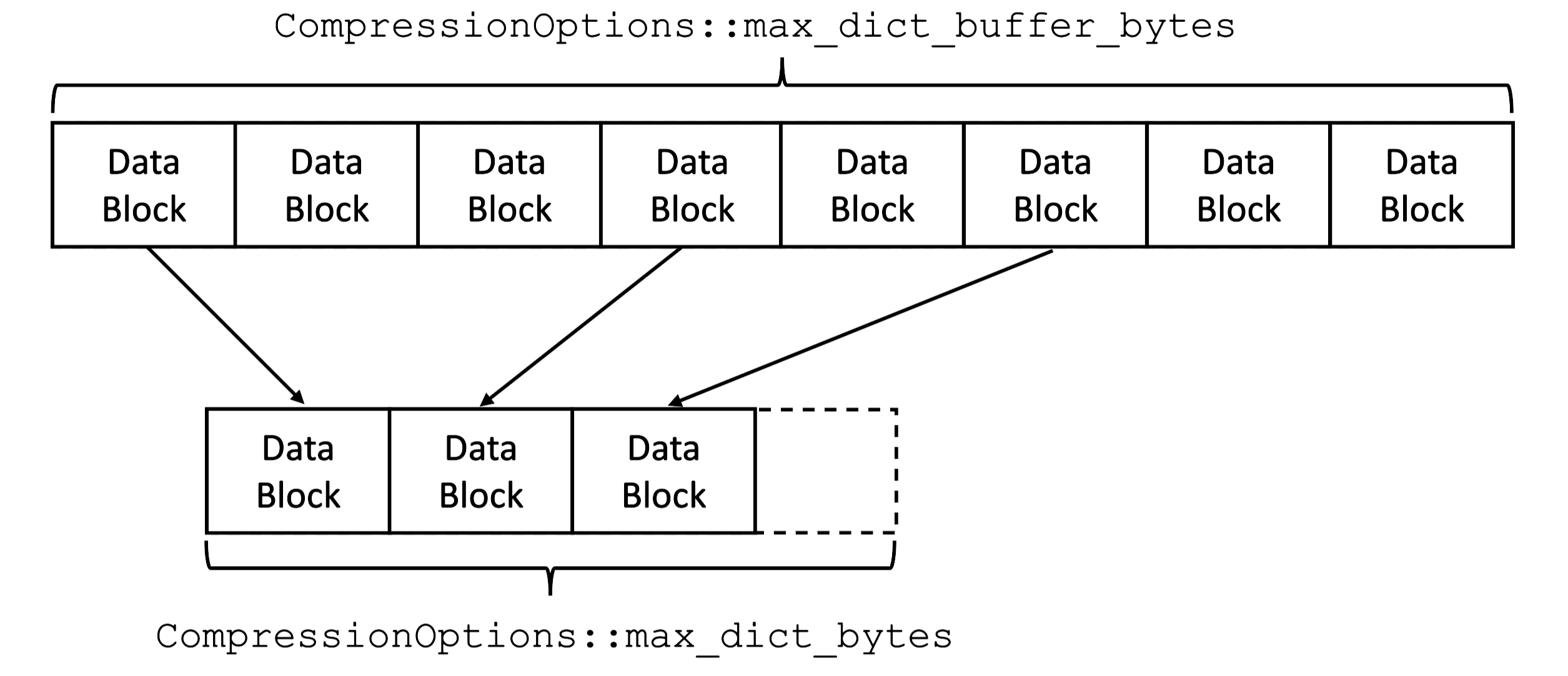
Raw samples mode (`zstd_max_train_bytes == 0`)
As mentioned earlier, the approach we took is to build the dictionary from buffered uncompressed data blocks. The first row of data blocks in these diagrams illustrate this buffering. The second row illustrates training samples selected from the buffered blocks. In raw samples mode (above), the final dictionary is simply the concatenation of these samples. Whereas, in zstd training mode (below), these samples will be passed to the trainer to produce the final dictionary.
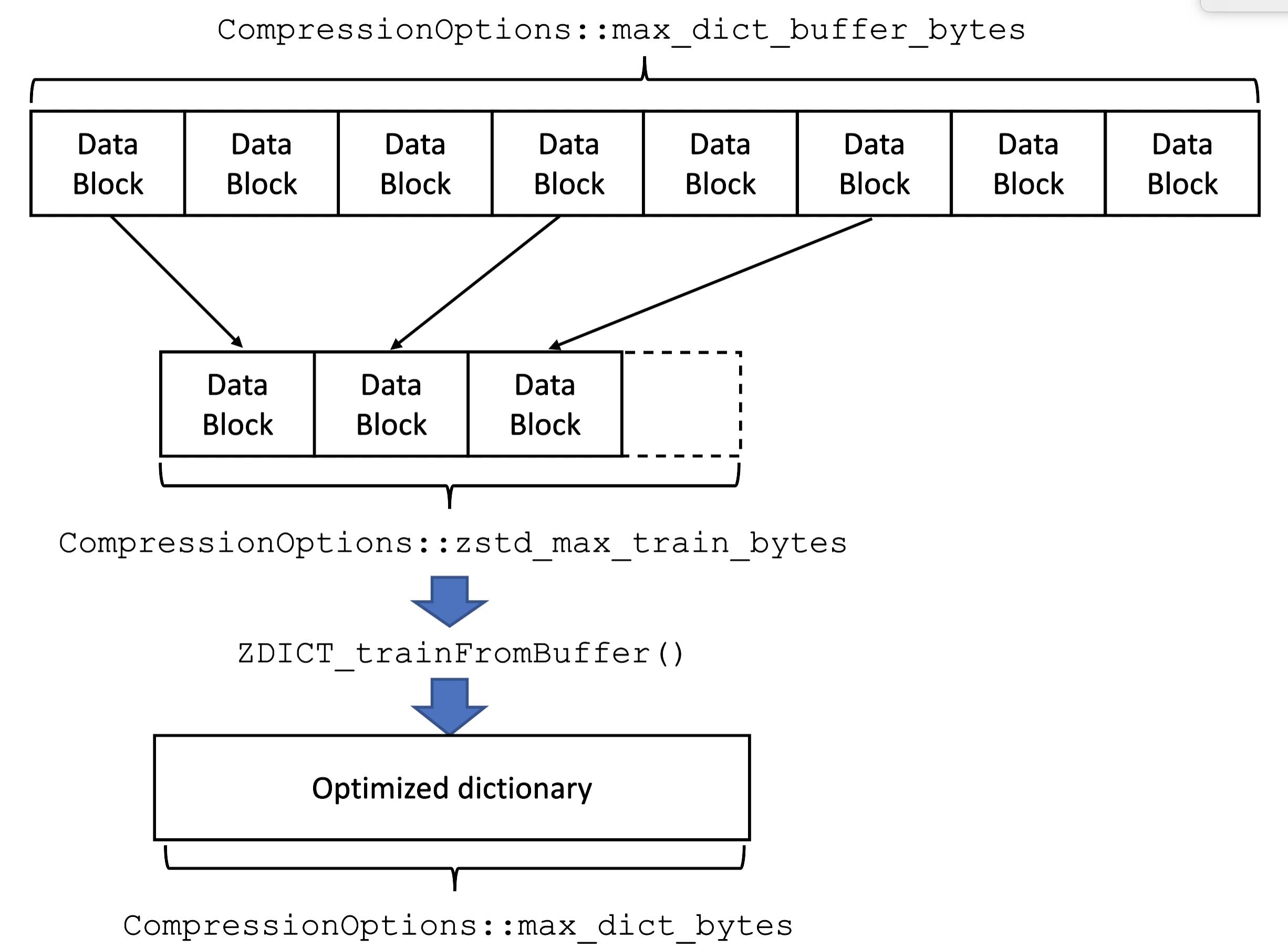
zstd training mode (`zstd_max_train_bytes > 0`)
Compression path
Once the preset dictionary is generated by the above process, we apply it to the buffered data blocks and write them to the output file. Thereafter, newly generated data blocks are immediately compressed and written out.
One optimization here is available to zstd v0.7.0+ users.
Instead of deserializing the dictionary on each compress invocation, we can do that work once and reuse it.
A ZSTD_CDict holds this digested dictionary state and is passed to the compress API.
Persistence
When an SST file’s data blocks are compressed using a preset dictionary, that dictionary is stored inside the file for later use in decompression.
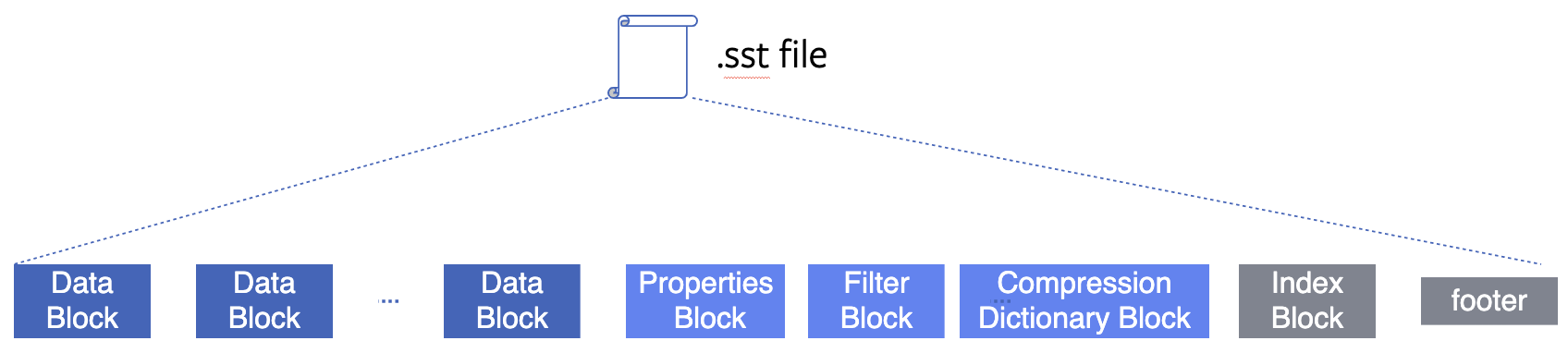
SST file layout with the preset dictionary in its own (uncompressed) block
Decompression path
To decompress, we need to provide both the data block and the dictionary used to compress it. Since dictionaries are just blocks in a file, we access them through block cache. However this additional load on block cache can be problematic. It can be alleviated by pinning the dictionaries to avoid going through the LRU locks.
An optimization analogous to the digested dictionary exists for certain zstd users (see User API section for details).
When enabled, the block cache stores the digested dictionary state for decompression (ZSTD_DDict) instead of the block contents.
In some cases we have seen decompression CPU decrease overall when enabling dictionary thanks to this optimization.
Measurement
Typically our first step in evaluating a candidate use case is an offline analysis of the data.
This gives us a quick idea whether presetting dictionary will be beneficial without any code, config, or data changes.
Our sst_dump tool reports what size SST files would have been using specified compression libraries and options.
We can select random SST files and compare the size with vs. without dictionary.
When that goes well, the next step is to see how it works in a live DB, like a production shadow or canary. There we can observe how it affects application/system metrics.
Even after dictionary is enabled, there is the question of how much space was finally saved. We provide a way to A/B test size with vs. without dictionary while running in production. This feature picks a sample of data blocks to compress in multiple ways – one of the outputs is stored, while the other outputs are thrown away after counting their size. Due to API limitations, the stored output always has to be the dictionary-compressed one, so this feature can only be used after enabling dictionary. The size with and without dictionary are stored in the SST file as table properties. These properties can be aggregated across all SST files in a DB (and across all DBs in a tier) to learn the final space saving.
User API
RocksDB allows presetting compression dictionary for users of LZ4, zstd, and zlib. The most advanced capabilities are available to zstd v1.1.4+ users who statically link (see below). Newer versions of zstd (v1.3.6+) have internal changes to the dictionary trainer and digested dictionary management, which significantly improve memory and CPU efficiency.
Run-time settings:
CompressionOptions::max_dict_bytes: Limit on per-SST file dictionary size. Increasing this causes dictionaries to consume more space and memory for the possibility of better data block compression. A typical value we use is 16KB.- (zstd only)
CompressionOptions::zstd_max_train_bytes: Limit on training data passed to zstd dictionary trainer. Larger values cause the training to consume more CPU (and take longer) while generating more effective dictionaries. The starting point guidance we received from zstd team is to set it to 100xCompressionOptions::max_dict_bytes. CompressionOptions::max_dict_buffer_bytes: Limit on data buffering from which training samples are gathered. By default we buffer up to the target file size per ongoing background job. If this amount of memory is concerning, this option can constrain the buffering with the downside that training samples will cover a smaller portion of the SST file. Work is ongoing to charge this memory usage to block cache so it will not need to be accounted for separately.BlockBasedTableOptions::cache_index_and_filter_blocks: Controls whether metadata blocks including dictionary are accessed through block cache or held in table reader memory (yes, its name is outdated).BlockBasedTableOptions::metadata_cache_options: Controls what metadata blocks are pinned in block cache. Pinning avoids LRU contention at the risk of cold blocks holding memory.ColumnFamilyOptions::sample_for_compression: Controls frequency of measuring extra compressions on data blocks using various libraries with default settings (i.e., without preset dictionary).
Compile-time setting:
- (zstd only)
EXTRA_CXXFLAGS=-DZSTD_STATIC_LINKING_ONLY: Hold digested dictionaries in block cache to save repetitive deserialization overhead. This saves a lot of CPU for read-heavy workloads. This compiler flag is necessary because one of the digested dictionary APIs we use is marked as experimental. We still use it in production, however.
Function:
DB::GetPropertiesOfAllTables(): The propertieskSlowCompressionEstimatedDataSizeandkFastCompressionEstimatedDataSizeestimate what the data block size (kDataSize) would have been if the corresponding compression library had been used. These properties are only present whenColumnFamilyOptions::sample_for_compressioncauses one or more samples to be measured, and they become more accurate with higher sampling frequency.
Tool:
sst_dump --command=recompress: Offline analysis tool that reports what the SST file size would have been using the specified compression library and options.