Range Tombstone Conversion: Faster Scans Over Long Runs of Deletes
RocksDB has historically been known for poor performance when tombstones accumulate. This has become a common problem within Meta, and the community has raised it as well. Here, we introduce an optimization that attempts to convert contiguous tombstones into a range tombstone during scans. As a result, instead of skipping through N tombstones, we only need to skip through a single range tombstone.
Background: point tombstones and range tombstones
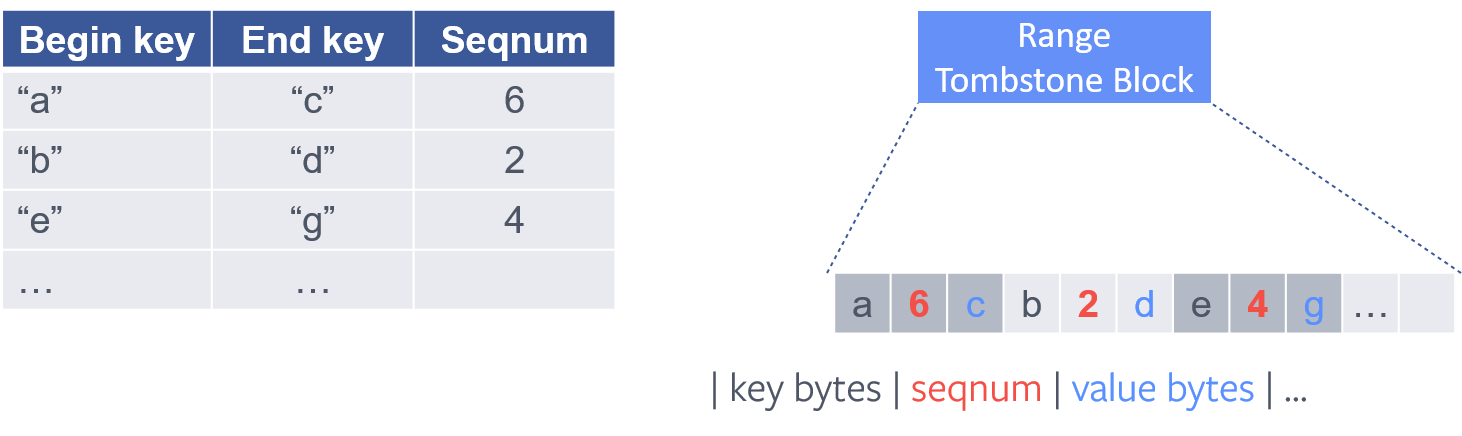
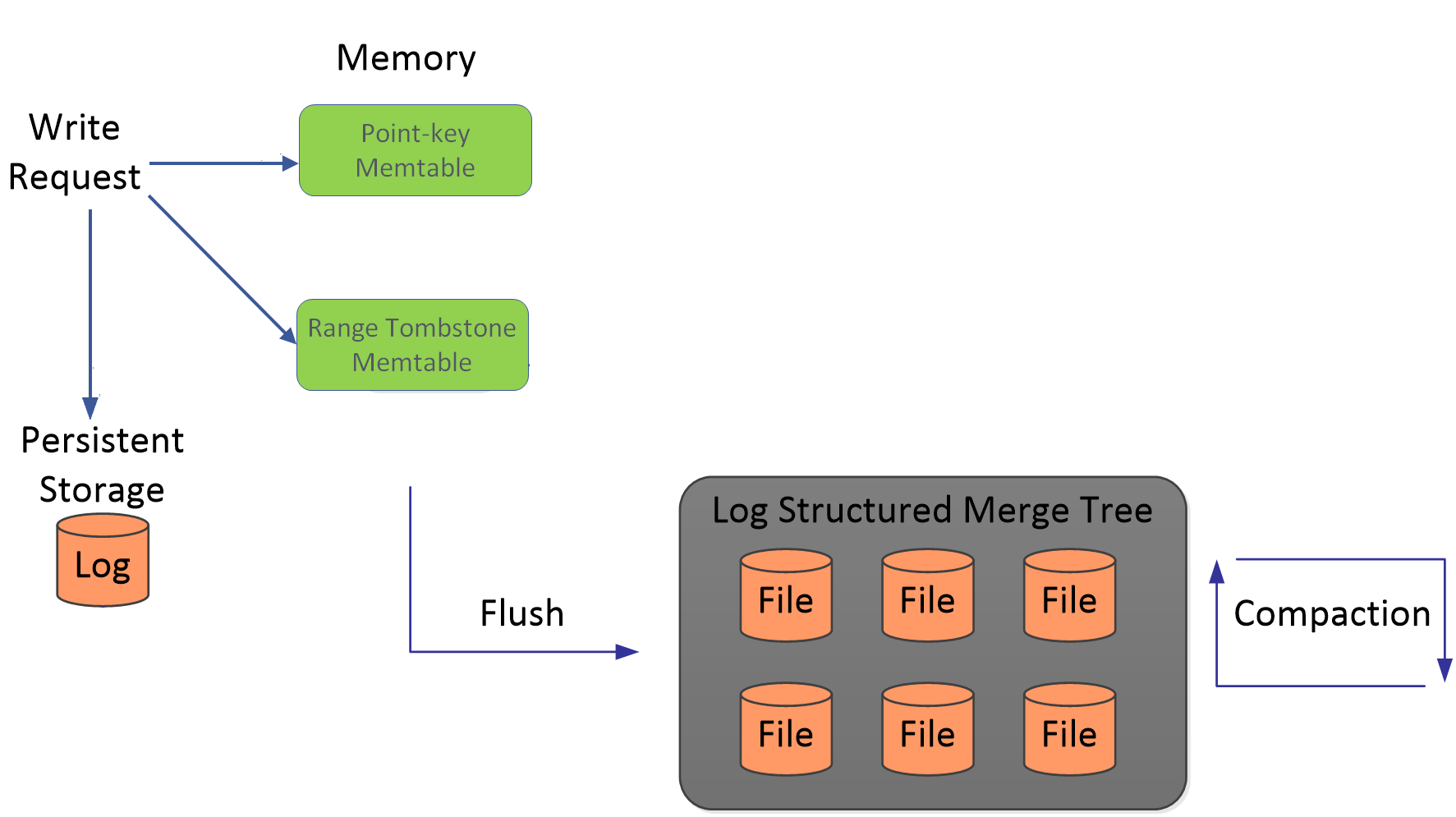
RocksDB is an LSM-tree, so a delete does not erase data in place. It writes a tombstone: a marker that shadows older values. A point tombstone (from Delete or SingleDelete) shadows exactly one key, while a range tombstone (from DeleteRange) shadows an entire half-open key range [start, end) with a single entry. Because newer data (usually) sits above older data in the tree, a read merges from the top down and takes the first entry it finds for a key, so a tombstone at an upper level hides any value for that key, or for any key in a range tombstone’s span, at the levels below.

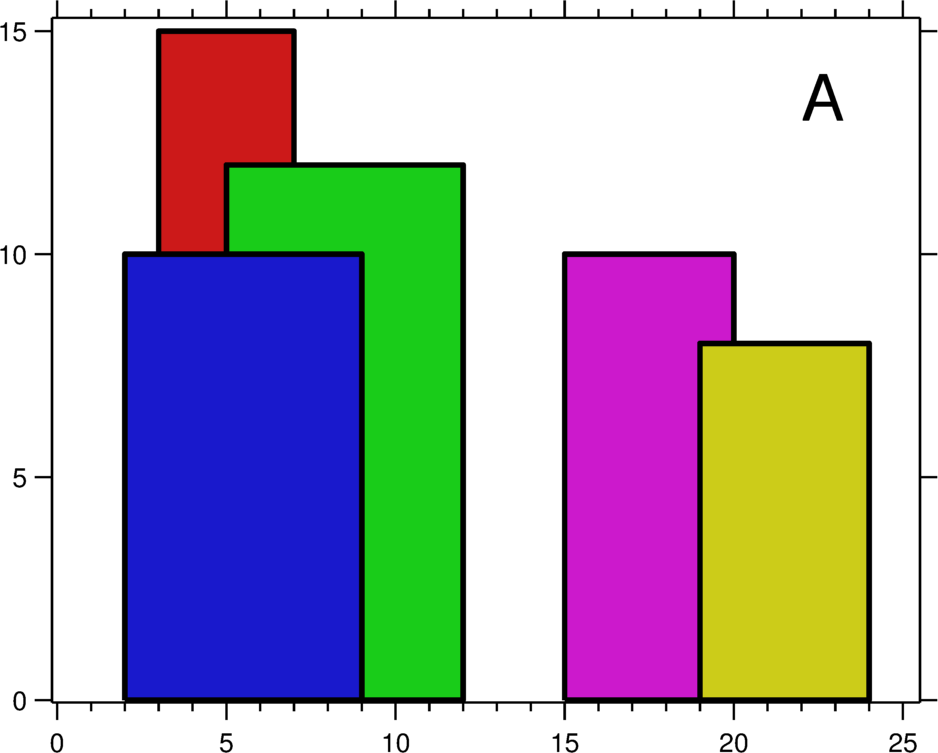
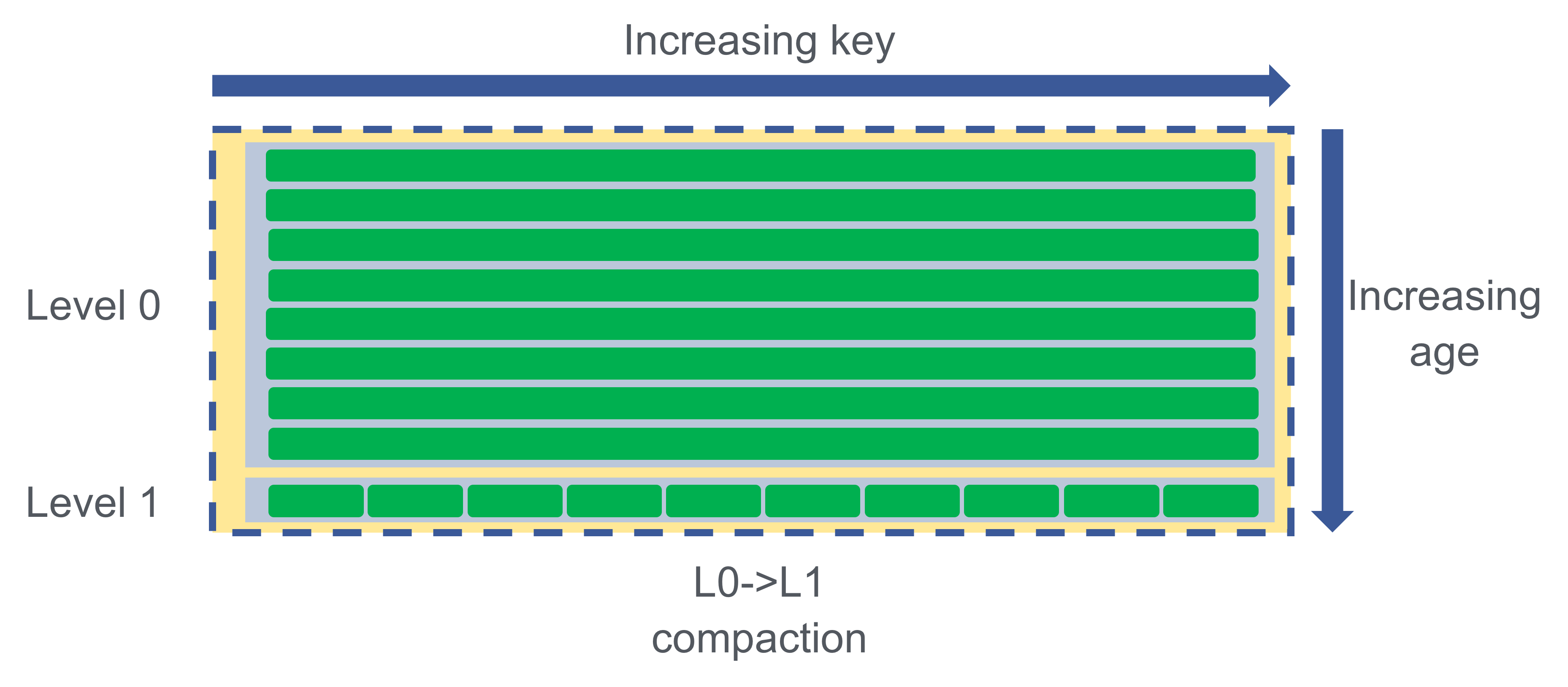
Point and range tombstones hide the values below them. The scan steps over each point tombstone but skips the range tombstone in one hop, and only the live keys (a, e, j) are returned to the user.
In both cases the space is reclaimed only later, during compaction, and only once the tombstone reaches the bottommost level with no live snapshot still needing it. Until then the tombstones sit in the way of reads. A scan never returns a deleted key, but to work out which keys are live it still has to step through every entry in key order. A point tombstone is just an ordinary entry, so the scan walks each one individually, and a run of N point tombstones costs N steps. A range tombstone is different: it is a single entry that covers the whole span, so when a scan reaches it, it can skip straight to the end of the range in one step instead of walking every key inside.
Existing solutions
A bulk delete leaves a region of the key space full of tombstones, and until compaction removes them, every scan across that region pays for them. The iterator steps over each point tombstone in turn to reach the live keys, because a run of point tombstones is just ordinary consecutive keys with no shortcut. That is O(N) in the number of dead entries, paid on every scan, and N grows with the size of the deleted region. The natural question is whether we can simply get rid of the tombstones faster, and RocksDB already gives you a few tools for that.
Deletion-triggered compaction. NewCompactOnDeletionCollectorFactory marks an SST file for compaction once it holds a high density of tombstones (at least D deletions within any N consecutive entries, or a whole-file tombstone ratio above a threshold), so RocksDB schedules those files for compaction sooner than the normal LSM compaction schedule would.
Scan-triggered memtable flush. memtable_op_scan_flush_trigger (and its averaged sibling memtable_avg_op_scan_flush_trigger) flush the active memtable once a single iterator operation scans through too many invisible entries (tombstones or shadowed values), moving them into an SST where deletion-triggered compaction can then clean them up. The two are designed to be used together.
These all help, but they share the same limitations, because they all work by removing tombstones through flush and compaction:
- They are reactive and asynchronous. Compaction runs in the background; a scan happening right now, before compaction catches up, still pays the full cost.
- They add write amplification. Every extra flush and compaction is more I/O and CPU spent rewriting data.
- They are defeated by a long-lived snapshot. Compaction can only drop a tombstone when no snapshot still needs the data it shadows, so a backup, a long analytics query, or replication holding a snapshot forces RocksDB to keep every tombstone created during that snapshot’s lifetime, no matter how aggressively you schedule compaction. This is both the case where tombstones pile up the most and the case these tools cannot fix.
The naive fix
The tempting fix is to notice a long run of contiguous point tombstones (say, during a flush or a compaction) and simply replace it with a single range tombstone. One entry instead of N, and reads skip it. Done.
The catch is visibility. A flush sees a single memtable; a compaction sees only the levels it happens to be merging. From that partial vantage, a run of tombstones can look perfectly contiguous even though live keys sit between them at other levels. Remember that a point tombstone shadows only its own key, while a range tombstone shadows everything in its span. So collapsing a locally-contiguous run into a range tombstone can delete live data that the original point tombstones never touched.

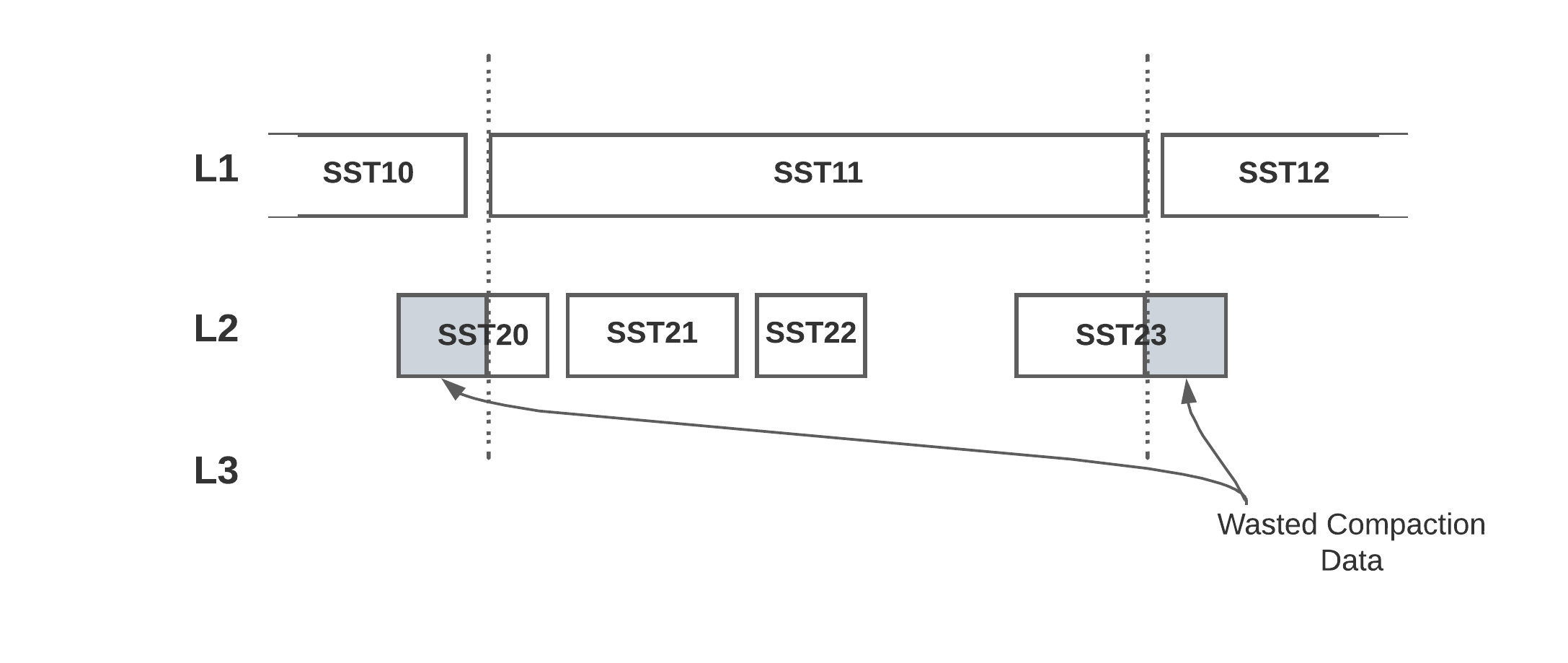
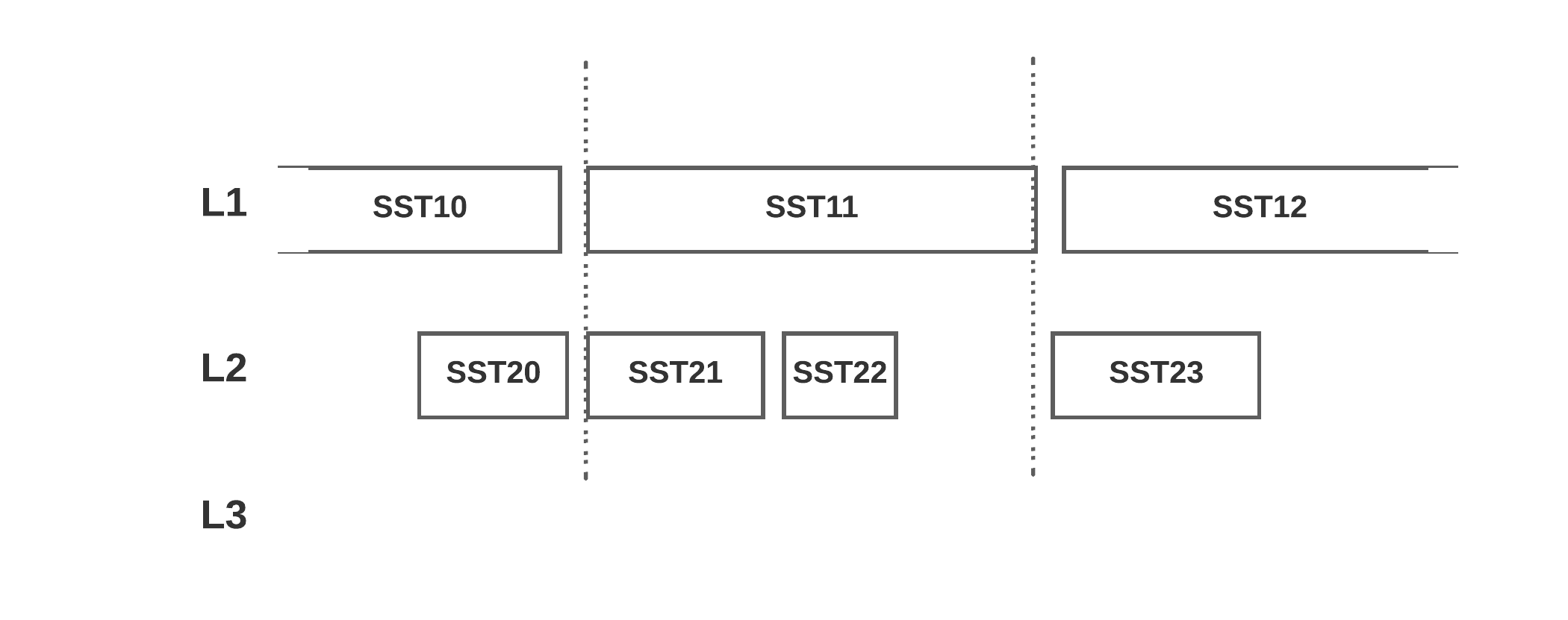
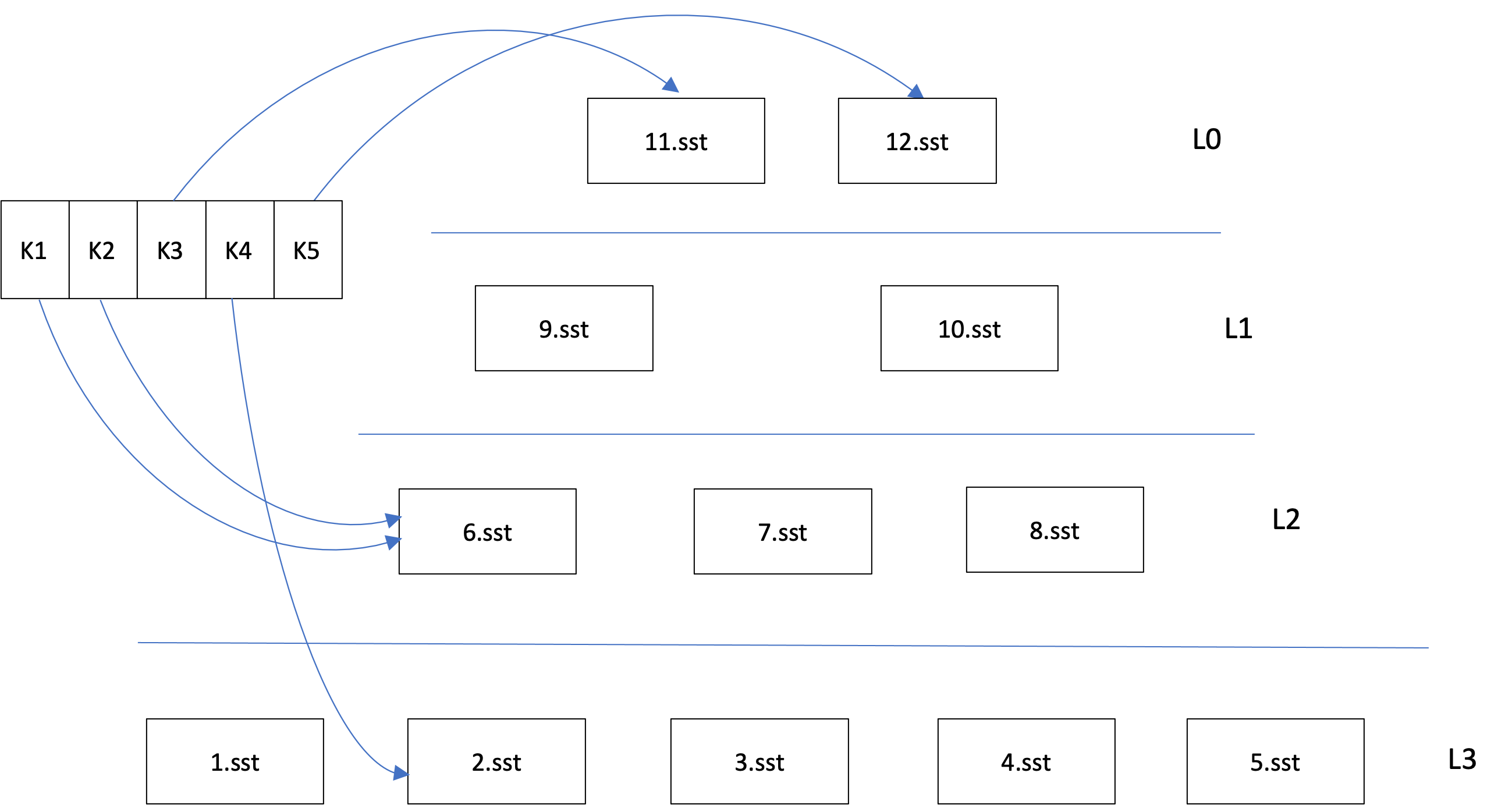
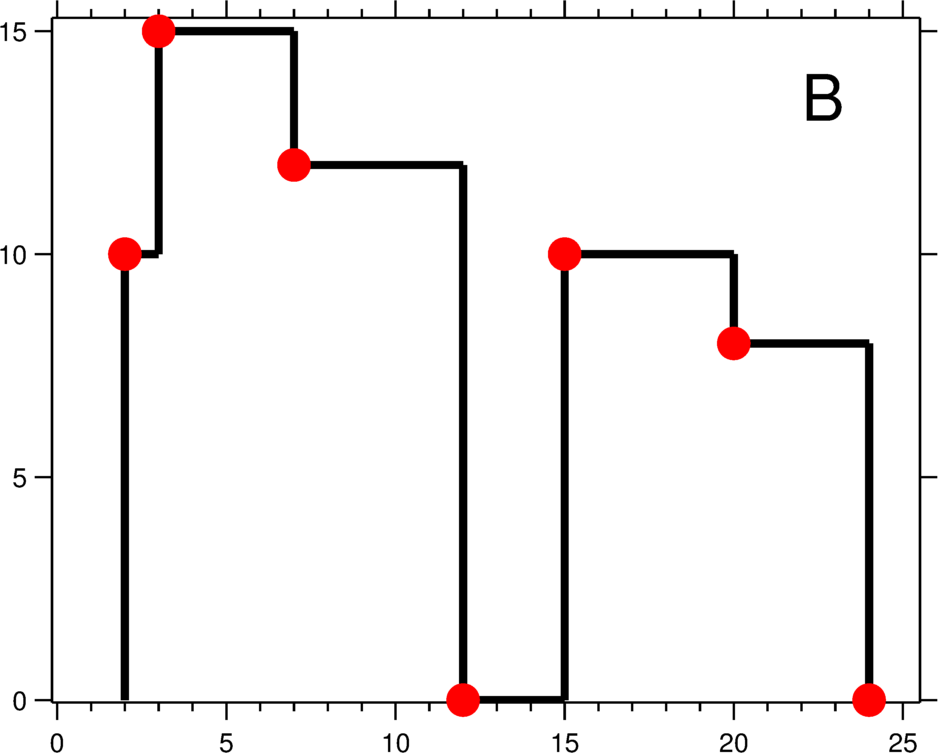
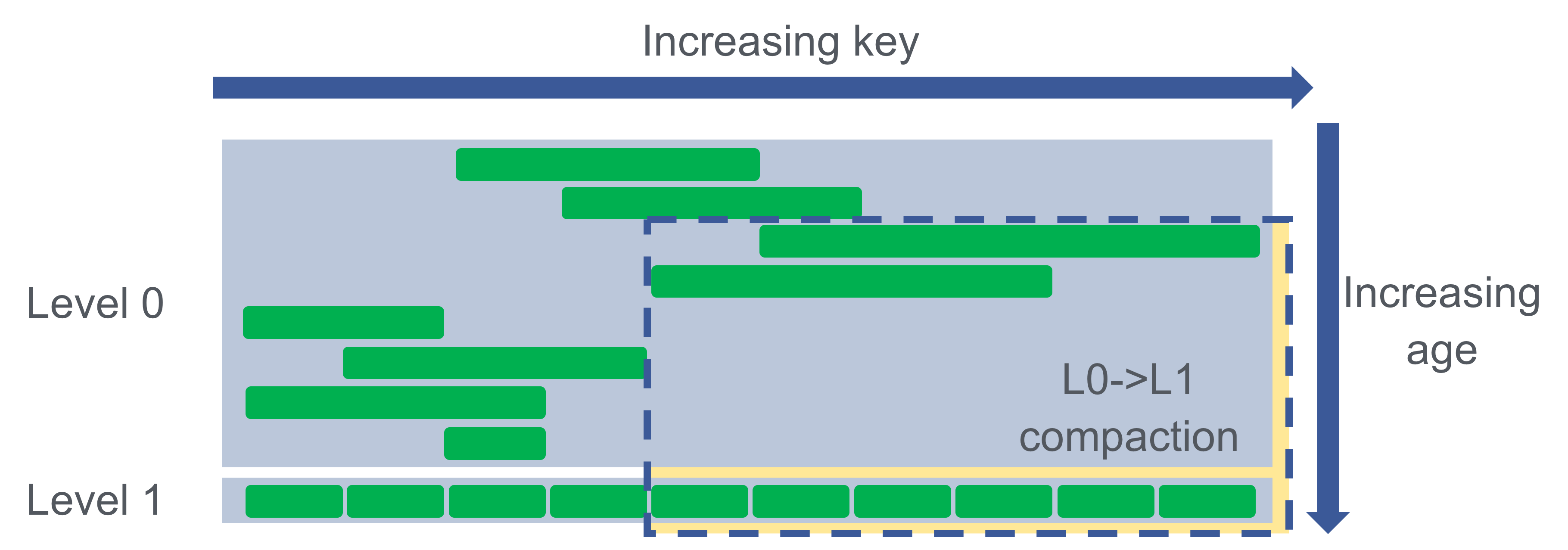
On the LSM the L0 tombstones look contiguous, but live keys sit one level below; collapsing them into a range tombstone would delete that live data.
In the figure, L0 holds tombstones for 10, 20, and 30 that look contiguous, with 40 the next live key just past them, but 15, 25, and 35 are live one level down in L1. A naive range tombstone over [10, 40) would also erase 15, 25, and 35. Only something that can see the entire LSM at once can tell whether a run of deletes is truly contiguous.
Application iterators
A read iterator merges every source (the mutable and immutable memtables and every SST level) into one ordered, snapshot-consistent stream of the keys actually visible at the read’s sequence number. As long as the scan can observe every interior live key, this gives a global view of the database, so the iterator can safely decide whether a run of point tombstones can be converted into a range tombstone (at the same snapshot sequence number, of course). That full-visibility requirement is also why the feature disables itself for table_filter, partial-timestamp reads, and prefix iterators that are neither total-order nor bounded by prefix_same_as_start.
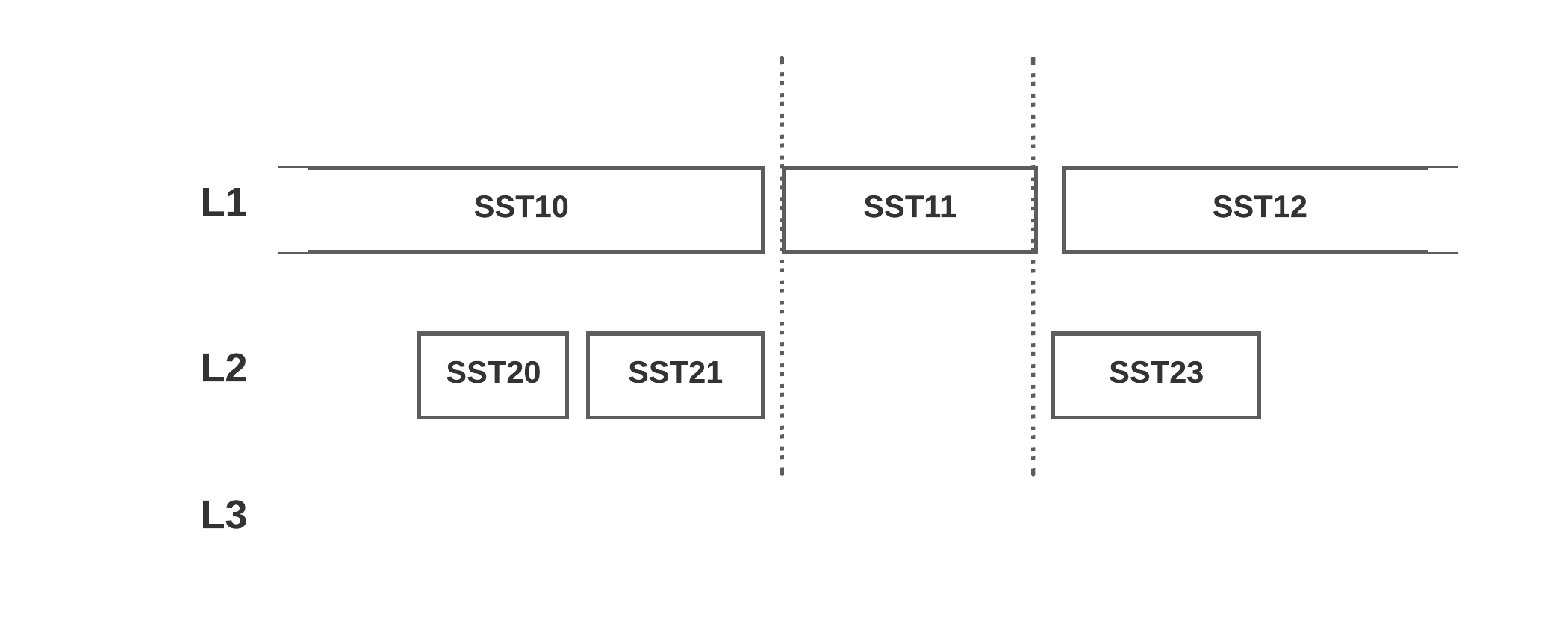
As the iterator moves forward (or backward) across contiguous point tombstones with no live key in between, it synthesizes a single range tombstone [first_tombstone_key, next_live_key) and inserts it into the mutable memtable using the same sequence number as the iterator is using to read the LSM.

Before: the run’s point tombstones are spread across levels. After: the scan adds one range tombstone to the memtable that summarizes them. The point tombstones remain, but later scans hit the range tombstone first and skip the run.
The inserted tombstone is logically redundant: those keys were already deleted, so it changes no query’s result and is purely a performance optimization. A conversion is not always guaranteed to succeed: there are numerous guards that discard one to avoid corrupting the database. See the comments on min_tombstones_for_range_conversion for details.
Because the tombstone lives in the memtable, it follows the normal lifecycle from there: it flushes to an SST and is eventually compacted away together with the point tombstones it summarizes, once no snapshot needs them. The cost is one redundant entry; the benefit is repaid across every scan in between.
Enabling it
Range tombstone conversion landed in PR #14448 (plus a few additional follow-up bug fixes) and is available in RocksDB 11.3.0 and later. It is controlled by the column-family option min_tombstones_for_range_conversion: the minimum length of a contiguous point-tombstone run that triggers a conversion. The default is 0, which disables the feature. Set it to a positive value to turn it on; the option is dynamically changeable through SetOptions, so you can enable or tune it without reopening the database.
1
2
3
4
5
6
7
Options options;
// Convert a run into a range tombstone once 100 contiguous
// point tombstones are seen with no live key between them.
options.min_tombstones_for_range_conversion = 100;
// Or change it dynamically on a running DB:
db->SetOptions(min_tombstones_for_range_conversion);
Pick the threshold to match your workload: a higher value restricts conversions to genuinely long runs, where the payoff is largest, and avoids adding redundant tombstones for short gaps.
Two statistics tickers let you see the feature at work:
rocksdb.read.path.range.tombstones.insertedcounts the range tombstones synthesized by conversion.rocksdb.read.path.range.tombstones.discardedcounts the attempts that were discarded for safety reasons.
Performance
The optimization targets read workloads over data that has accumulated tombstones. To measure it we use the following db_bench setup: fill and compact a database, scatter sets of contiguous point deletes through it, then run a seekrandom scan with conversion off versus on.
1
2
3
4
5
6
7
8
9
10
11
# Fill and compact 1M keys
./db_bench --benchmarks=fillseq,compact --compression_type=none --num=1000000 --db=$DB
# Scatter tombstones: seek to random keys and delete 100 keys after each seek
./db_bench --benchmarks=seekrandom,flush --compression_type=none --num=2000 \
--seek_nexts=0 --seek_nexts_to_delete=100 --use_existing_db=1 --threads=1 --db=$DB
# Scan workload: forward or reverse, conversion off (=0) or on (=8)
./db_bench --benchmarks=seekrandom --seek_nexts=100 --threads=8 --reverse_iterator=<true|false> \
--use_existing_db=1 --compression_type=none --num=1000000 --duration=10 \
--disable_auto_compactions --min_tombstones_for_range_conversion=<0|8> --db=$DB
seekrandom over the delete-heavy database, throughput in ops/s:
| Workload | Conversion off | Conversion on | Speedup |
|---|---|---|---|
| Forward scan | 2,685 | 266,733 | ~99x |
| Reverse scan | 519 | 191,119 | ~368x |
Regression check
Enabling the feature adds a little per-scan bookkeeping (it tracks runs of contiguous tombstones) even on scans that never convert anything, so it is worth confirming there is no slowdown when there are no tombstones to collapse. Here we fill and compact without scattering any deletes, then run the same scan with conversion off versus on:
1
2
3
4
5
6
7
# Fill and compact 1M keys, no deletes
./db_bench --benchmarks=fillseq,compact --compression_type=none --num=1000000 --db=$DB
# Same scan workload: forward or reverse, conversion off (=0) or on (=8)
./db_bench --benchmarks=seekrandom --seek_nexts=100 --threads=8 --reverse_iterator=<true|false> \
--use_existing_db=1 --compression_type=none --num=1000000 --duration=10 \
--disable_auto_compactions --min_tombstones_for_range_conversion=<0|8> --db=$DB
| Workload | Conversion off | Conversion on | Speedup |
|---|---|---|---|
| Forward scan, no deletes | 310,052 | 311,185 | no change (within noise) |
| Reverse scan, no deletes | 237,484 | 236,541 | no change (within noise) |
Throughput is unchanged, so the bookkeeping is cheap and the feature is safe to leave enabled for mixed workloads.