
Indexing SST Files for Better Lookup Performance
For a Get() request, RocksDB goes through mutable memtable, list of immutable memtables, and SST files to look up the target key. SST files are organized in levels.
On level 0, files are sorted based on the time they are flushed. Their key range (as defined by FileMetaData.smallest and FileMetaData.largest) are mostly overlapped with each other. So it needs to look up every L0 file.
Compaction is scheduled periodically to pick up files from an upper level and merges them with files from lower level. As a result, key/values are moved from L0 down the LSM tree gradually. Compaction sorts key/values and split them into files. From level 1 and below, SST files are sorted based on key. Their key range are mutually exclusive. Instead of scanning through each SST file and checking if a key falls into its range, RocksDB performs a binary search based on FileMetaData.largest to locate a candidate file that can potentially contain the target key. This reduces complexity from O(N) to O(log(N)). However, log(N) can still be large for bottom levels. For a fan-out ratio of 10, level 3 can have 1000 files. That requires 10 comparisons to locate a candidate file. This is a significant cost for an in-memory database when you can do several million gets per second.
One observation to this problem is that: after the LSM tree is built, an SST file’s position in its level is fixed. Furthermore, its order relative to files from the next level is also fixed. Based on this idea, we can perform fractional cascading kind of optimization to narrow down the binary search range. Here is an example:
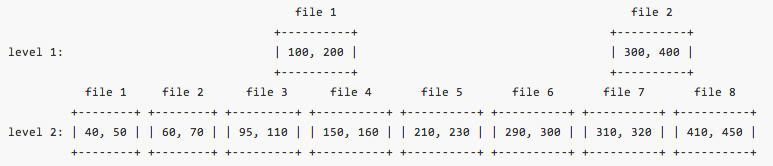
Level 1 has 2 files and level 2 has 8 files. Now, we want to look up key 80. A binary search based FileMetaData.largest tells you file 1 is the candidate. Then key 80 is compared with its FileMetaData.smallest and FileMetaData.largest to decide if it falls into the range. The comparison shows 80 is less than FileMetaData.smallest (100), so file 1 does not possibly contain key 80. We to proceed to check level 2. Usually, we need to do binary search among all 8 files on level 2. But since we already know target key 80 is less than 100 and only file 1 to file 3 can contain key less than 100, we can safely exclude other files from the search. As a result we cut down the search space from 8 files to 3 files.
Let’s look at another example. We want to get key 230. A binary search on level 1 locates to file 2 (this also implies key 230 is larger than file 1’s FileMetaData.largest 200). A comparison with file 2’s range shows the target key is smaller than file 2’s FileMetaData.smallest 300. Even though, we couldn’t find key on level 1, we have derived hints that target key is in range between 200 and 300. Any files on level 2 that cannot overlap with [200, 300] can be safely excluded. As a result, we only need to look at file 5 and file 6 on level 2.
Inspired by this concept, we pre-build pointers at compaction time on level 1 files that point to a range of files on level 2. For example, file 1 on level 1 points to file 3 (on level 2) on the left and file 4 on the right. File 2 will point to level 2 files 6 and 7. At query time, these pointers are used to determine the actual binary search range based on comparison result.
Our benchmark shows that this optimization improves lookup QPS by ~5% for similar setup mentioned here.