
Level-based Compaction Changes
Introduction
RocksDB provides an option to limit the number of L0 files, which bounds read-amplification. Since L0 files (unlike files at lower levels) can span the entire key-range, a key might be in any file, thus reads need to check them one-by-one. Users often wish to configure a low limit to improve their read latency.
Although, the mechanism with which we enforce L0’s file count limit may be unappealing. When the limit is reached, RocksDB intentionally delays user writes. This slows down accumulation of files in L0, and frees up resources for compacting files down to lower levels. But adding delays will significantly increase user-visible write latency jitter.
Also, due to how L0 files can span the entire key-range, compaction parallelization is limited. Files at L0 or L1 may be locked due to involvement in pending L0->L1 or L1->L2 compactions. We can only schedule a parallel L0->L1 compaction if it does not require any of the locked files, which is typically not the case.
To handle these constraints better, we added a new type of compaction, L0->L0. It quickly reduces file count in L0 and can be scheduled even when L1 files are locked, unlike L0->L1. We also changed the L0->L1 picking algorithm to increase opportunities for parallelism.
Old L0->L1 Picking Logic
Previously, our logic for picking which L0 file to compact was the same as every other level: pick the largest file in the level. One special property of L0->L1 compaction is that files can overlap in the input level, so those overlapping files must be pulled in as well. For example, a compaction may look like this:
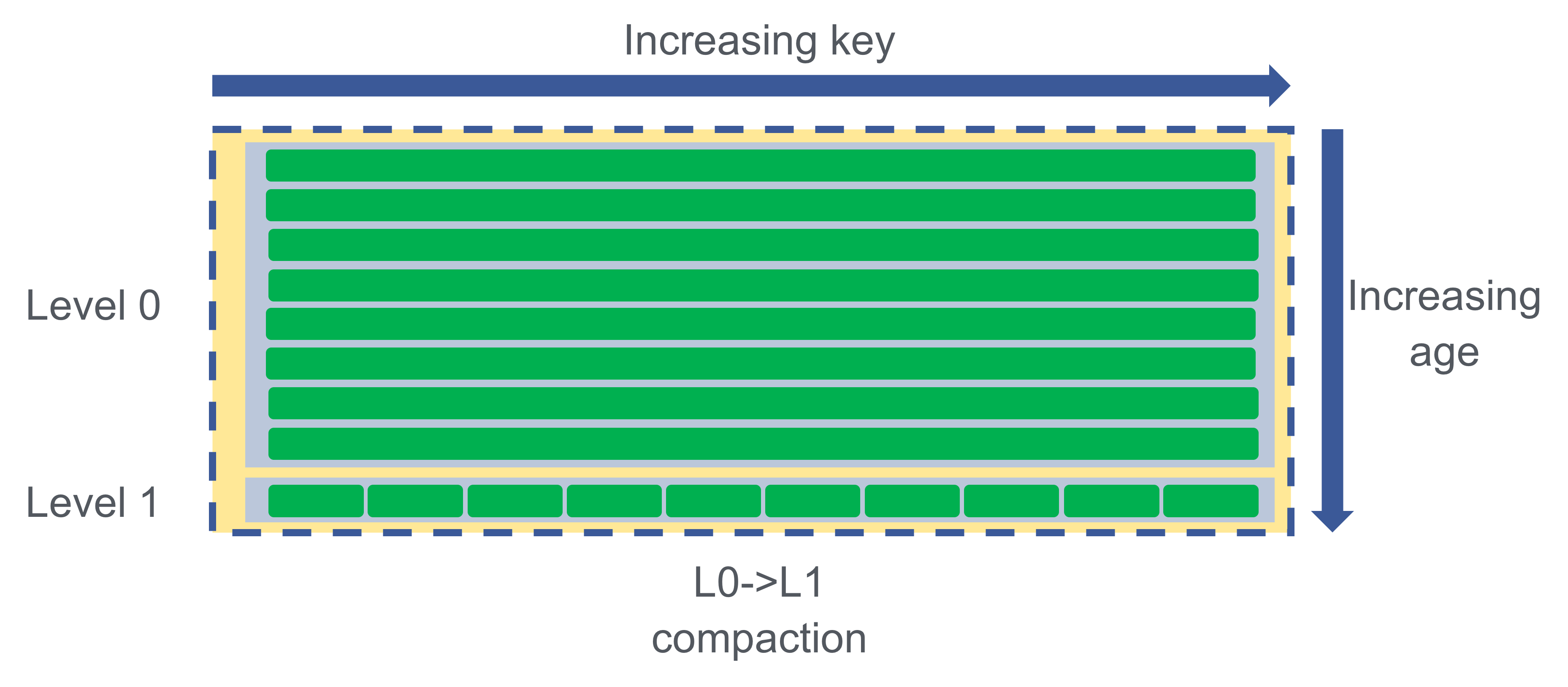
This compaction pulls in every L0 and L1 file. This happens regardless of which L0 file is initially chosen as each file overlaps with every other file.
Users may insert their data less uniformly in the key-range. For example, a database may look like this during L0->L1 compaction:
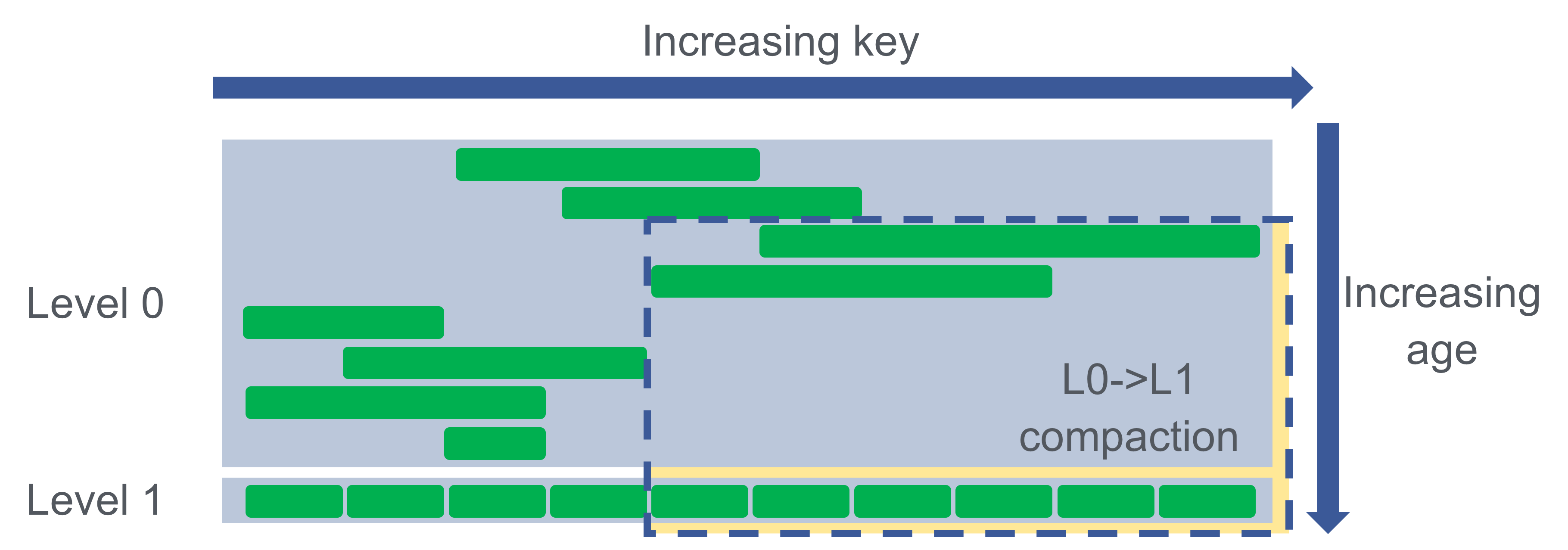
Let’s say the third file from the top is the largest, and let’s say the top two files are created after the compaction started. When the compaction is picked, the fourth L0 file and six rightmost L1 files are pulled in due to overlap. Notice this leaves the database in a state where we might not be able to schedule parallel compactions. For example, if the sixth file from the top is the next largest, we can’t compact it because it overlaps with the top two files, which overlap with the locked L0 files.
We can now see the high-level problems with this approach more clearly. First, locked files in L0 or L1 prevent us from parallelizing compactions. When locked files block L0->L1 compaction, there is nothing we can do to eliminate L0 files. Second, L0->L1 compactions are relatively slow. As we saw, when keys are uniformly distributed, L0->L1 compacts two entire levels. While this is happening, new files are being flushed to L0, advancing towards the file count limit.
New L0->L0 Algorithm
We introduced compaction within L0 to improve both parallelization and speed of reducing L0 file count. An L0->L0 compaction may look like this:
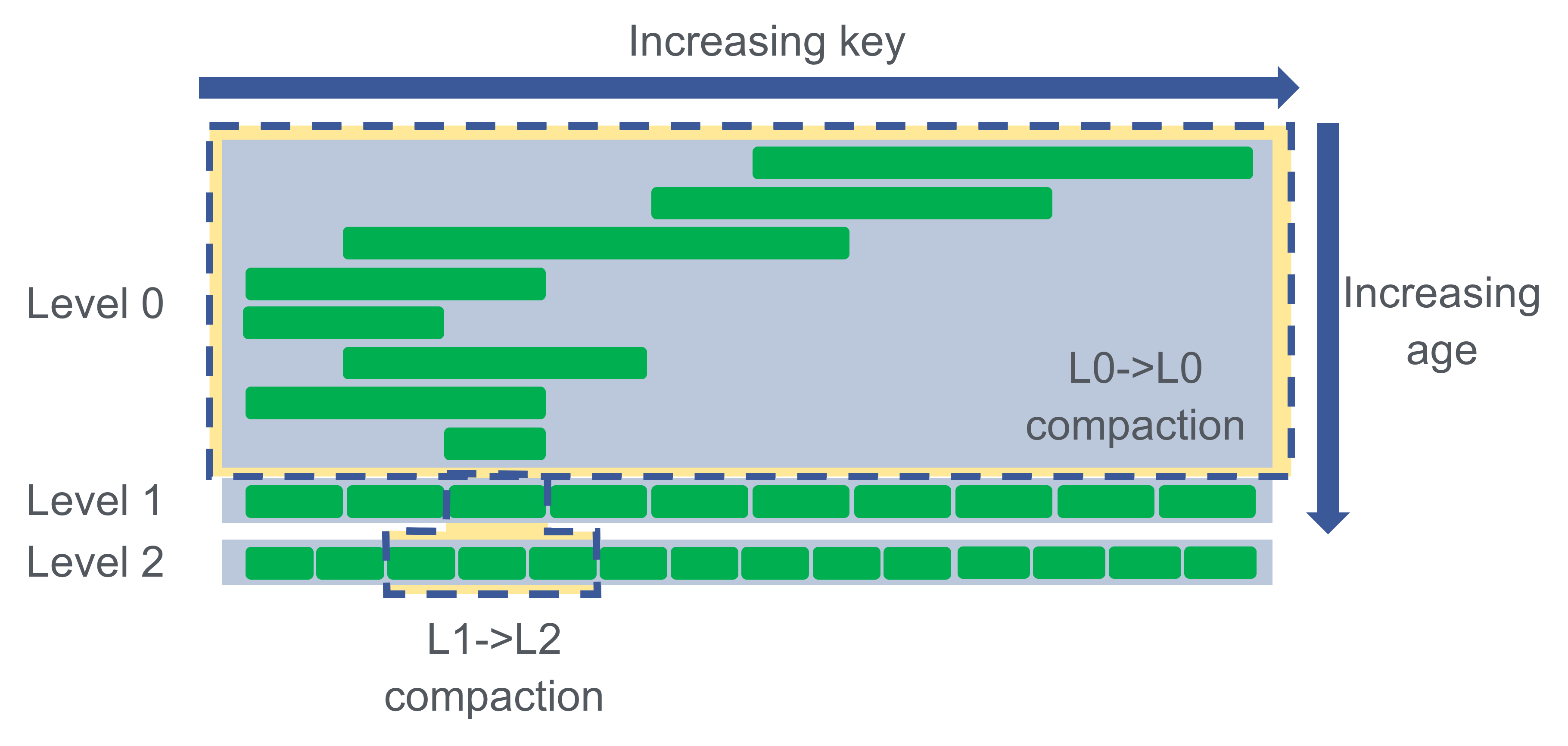
Say the L1->L2 compaction started first. Now L0->L1 is prevented by the locked L1 file. In this case, we compact files within L0. This allows us to start the work for eliminating L0 files earlier. It also lets us do less work since we don’t pull in any L1 files, whereas L0->L1 compaction would’ve pulled in all of them. This lets us quickly reduce L0 file count to keep read-amp low while sustaining large bursts of writes (i.e., fast accumulation of L0 files).
The tradeoff is this increases total compaction work, as we’re now compacting files without contributing towards our eventual goal of moving them towards lower levels. Our benchmarks, though, consistently show less compaction stalls and improved write throughput. One justification is that L0 file data is highly likely in page cache and/or block cache due to it being recently written and frequently accessed. So, this type of compaction is relatively cheap compared to compactions at lower levels.
This feature is available since RocksDB 5.4.
New L0->L1 Picking Logic
Recall how the old L0->L1 picking algorithm chose the largest L0 file for compaction. This didn’t fit well with L0->L0 compaction, which operates on a span of files. That span begins at the newest L0 file, and expands towards older files as long as they’re not being compacted. Since the largest file may be anywhere, the old L0->L1 picking logic could arbitrarily prevent us from getting a long span of files. See the second illustration in this post for a scenario where this would happen.
So, we changed the L0->L1 picking algorithm to start from the oldest file and expand towards newer files as long as they’re not being compacted. For example:
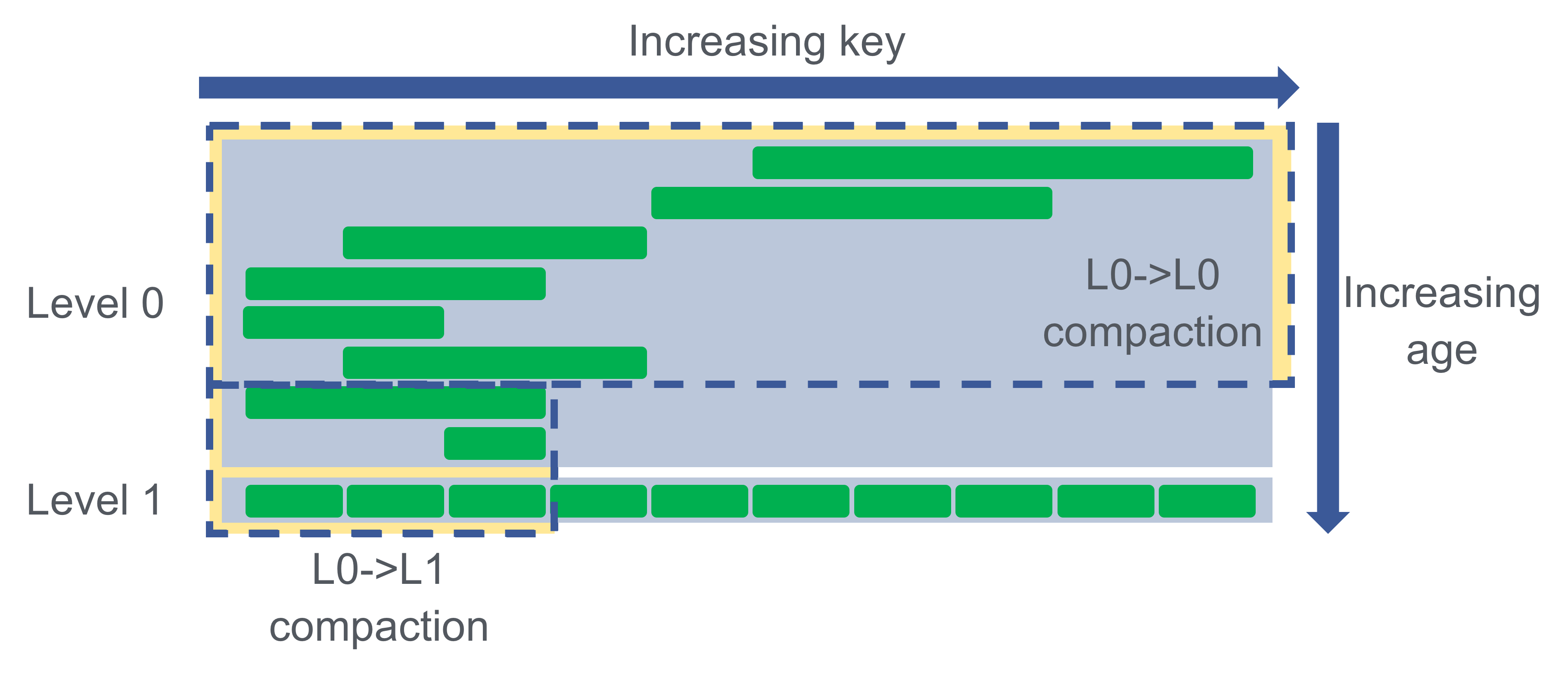
Now, there can never be L0 files unreachable for L0->L0 due to L0->L1 selecting files in the middle. When longer spans of files are available for L0->L0, we perform less compaction work per deleted L0 file, thus improving efficiency.
This feature will be available in RocksDB 5.7.
Performance Changes
Mark Callaghan did the most extensive benchmarking of this feature’s impact on MyRocks. See his results here. Note the primary change between his March 17 and April 14 builds is the latter performs L0->L0 compaction.