Integrated BlobDB
Background
BlobDB is essentially RocksDB for large-value use cases. The basic idea, which was proposed in the WiscKey paper, is key-value separation: by storing large values in dedicated blob files and storing only small pointers to them in the LSM tree, we avoid copying the values over and over again during compaction, thus reducing write amplification. Historically, BlobDB supported only FIFO and TTL based use cases that can tolerate some data loss. In addition, it was incompatible with many widely used RocksDB features, and required users to adopt a custom API. In 2020, we decided to rearchitect BlobDB from the ground up, taking the lessons learned from WiscKey and the original BlobDB but also drawing inspiration and incorporating ideas from other similar systems. Our goals were to eliminate the above limitations and to create a new integrated version that enables customers to use the well-known RocksDB API, has feature parity with the core of RocksDB, and offers better performance. This new implementation is now available and provides the following improvements over the original:
- API. In contrast with the legacy BlobDB implementation, which had its own
StackableDB-based interface (rocksdb::blob_db::BlobDB), the new version can be used via the well-knownrocksdb::DBAPI, and can be configured simply by using a few column family options. - Consistency. With the integrated BlobDB implementation, RocksDB’s consistency guarantees and various write options (like using the WAL or synchronous writes) now apply to blobs as well. Moreover, the new BlobDB keeps track of blob files in the RocksDB MANIFEST.
- Write performance. When using the old BlobDB, blobs are extracted and immediately written to blob files by the BlobDB layer in the application thread. This has multiple drawbacks from a performance perspective: first, it requires synchronization; second, it means that expensive operations like compression are performed in the application thread; and finally, it involves flushing the blob file after each blob. The new code takes a completely different approach by offloading blob file building to RocksDB’s background jobs, i.e. flushes and compactions. This means that similarly to SSTs, any given blob file is now written by a single background thread, eliminating the need for locking, flushing, or performing compression in the foreground. Note that this approach is also a better fit for network-based file systems where small writes might be expensive and opens up the possibility of file format optimizations that involve buffering (like dictionary compression).
- Read performance. The old code relies on each read (i.e.
Get,MultiGet, or iterator) taking a snapshot and uses those snapshots when deciding which obsolete blob files can be removed. The new BlobDB improves this by generalizing RocksDB’s Version concept, which historically referred to the set of live SST files at a given point in time, to include the set of live blob files as well. This has performance benefits like making the read path mostly lock-free by utilizing thread-local storage. We have also introduced a blob file cache that can be utilized to keep frequently accessed blob files open. - Garbage collection. Key-value separation means that if a key pointing to a blob gets overwritten or deleted, the blob becomes unreferenced garbage. To be able to reclaim this space, BlobDB now has garbage collection capabilities. GC is integrated into the compaction process and works by relocating valid blobs residing in old blob files as they are encountered during compaction. Blob files can be marked obsolete (and eventually deleted in one shot) once they contain nothing but garbage. This is more efficient than the method used by WiscKey, which involves performing a
Getoperation to find out whether a blob is still referenced followed by aPutto update the reference, which in turn results in garbage collection competing and potentially conflicting with the application’s writes. - Feature parity with the RocksDB core. The new BlobDB supports way more features than the original and is near feature parity with vanilla RocksDB. In particular, we support all basic read/write APIs (with the exception of
Merge, which is coming soon), recovery, compression, atomic flush, column families, compaction filters, checkpoints, backup/restore, transactions, per-file checksums, and the SST file manager. In addition, the new BlobDB’s options can be dynamically adjusted using theSetOptionsinterface.
API
The new BlobDB can be configured (on a per-column family basis if needed) simply by using the following options:
enable_blob_files: set it totrueto enable key-value separation.min_blob_size: values at or above this threshold will be written to blob files during flush or compaction.blob_file_size: the size limit for blob files.blob_compression_type: the compression type to use for blob files. All blobs in the same file are compressed using the same algorithm.enable_blob_garbage_collection: set this totrueto make BlobDB actively relocate valid blobs from the oldest blob files as they are encountered during compaction.blob_garbage_collection_age_cutoff: the threshold that the GC logic uses to determine which blob files should be considered “old.” For example, the default value of 0.25 signals to RocksDB that blobs residing in the oldest 25% of blob files should be relocated by GC. This parameter can be tuned to adjust the trade-off between write amplification and space amplification.
The above options are all dynamically adjustable via the SetOptions API; changing them will affect subsequent flushes and compactions but not ones that are already in progress.
In terms of compaction styles, we recommend using leveled compaction with BlobDB. The rationale behind universal compaction in general is to provide lower write amplification at the expense of higher read amplification; however, as we will see later in the Performance section, BlobDB can provide very low write amp and good read performance with leveled compaction. Therefore, there is really no reason to take the hit in read performance that comes with universal compaction.
In addition to the above, consider tuning the following non-BlobDB specific options:
write_buffer_size: this is the memtable size. You might want to increase it for large-value workloads to ensure that SST and blob files contain a decent number of keys.target_file_size_base: the target size of SST files. Note that even when using BlobDB, it is important to have an LSM tree with a “nice” shape and multiple levels and files per level to prevent heavy compactions. Since BlobDB extracts and writes large values to blob files, it makes sense to make this parameter significantly smaller than the memtable size. One guideline is to setblob_file_sizeto the same value aswrite_buffer_size(adjusted for compression if needed) and maketarget_file_size_baseproportionally smaller based on the ratio of key size to value size.max_bytes_for_level_base: consider setting this to a multiple (e.g. 8x or 10x) oftarget_file_size_base.
As mentioned above, the new BlobDB now also supports compaction filters. Key-value separation actually enables an optimization here: if the compaction filter of an application can make a decision about a key-value solely based on the key, it is unnecessary to read the value from the blob file. Applications can take advantage of this optimization by implementing the new FilterBlobByKey method of the CompactionFilter interface. This method gets called by RocksDB first whenever it encounters a key-value where the value is stored in a blob file. If this method returns a “final” decision like kKeep, kRemove, kChangeValue, or kRemoveAndSkipUntil, RocksDB will honor that decision; on the other hand, if the method returns kUndetermined, RocksDB will read the blob from the blob file and call FilterV2 with the value in the usual fashion.
Performance
We tested the performance of the new BlobDB for six different value sizes between 1 KB and 1 MB using a customized version of our standard benchmark suite on a box with an 18-core Skylake DE CPU (running at 1.6 GHz, with hyperthreading enabled), 64 GB RAM, a 512 GB boot SSD, and two 1.88 TB M.2 SSDs in a RAID0 configuration for data. The RocksDB version used was equivalent to 6.18.1, with some benchmarking and statistics related enhancements. Leveled and universal compaction without key-value separation were used as reference points. Note that for simplicity, we use “leveled compaction” and “universal compaction” as shorthand for leveled and universal compaction without key-value separation, respectively, and “BlobDB” for BlobDB with leveled compaction.
Our benchmarks cycled through six different workloads: two write-only ones (initial load and overwrite), two read/write ones (point lookup/write mix and range scan/write mix), and finally two read-only ones (point lookups and range scans). The first two phases performed a fixed amount of work (see below), while the final four were run for a fixed amount of time, namely 30 minutes each. Each phase other than the first one started with the database state left behind by the previous one. Here’s a brief description of the workloads:
- Initial load: this workload has two distinct stages, a single-threaded random write stage during which compactions are disabled (so all data is flushed to L0, where it remains for the rest of the stage), followed by a full manual compaction. The random writes are performed with load-optimized settings, namely using the vector memtable implementation and with concurrent memtable writes and WAL disabled. This stage was used to populate the database with 1 TB worth of raw values, e.g. 2^30 (~1 billion) 1 KB values or 2^20 (~1 million) 1 MB values.
- Overwrite: this is a multi-threaded random write workload using the usual skiplist memtable, with compactions, WAL, and concurrent memtable writes enabled. In our tests, 16 writer threads were used. The total number of writes was set to the same number as in the initial load stage and split up evenly between the writer threads. For instance, for the 1 MB value size, we had 2^20 writes divided up between the 16 threads, resulting in each thread performing 2^16 write operations. At the end of this phase, a “wait for compactions” step was added to prevent this workload from exhibiting artificially low write amp or conversely, the next phase showing inflated write amp.
- Point lookup/write mix: a single writer thread performing random writes while N (in our case, 16) threads perform random point lookups. WAL is enabled and all writes are synced.
- Range scan/write mix: similar to the above, with one writer thread and N reader threads (where N was again set to 16 in our tests). The reader threads perform random range scans, with 10
Nextcalls perSeek. Again, WAL is enabled, and sync writes are used. - Point lookups (read-only): N=16 threads perform random point lookups.
- Range scans (read-only): N=16 threads execute random range scans, with 10
Nexts perSeeklike above.
With that out of the way, let’s see how the new BlobDB performs against traditional leveled and universal compaction. In the next few sections, we’ll be looking at write amplification as well as read and write performance. We’ll also briefly compare the write performance of the new BlobDB with the legacy implementation.
Write amplification
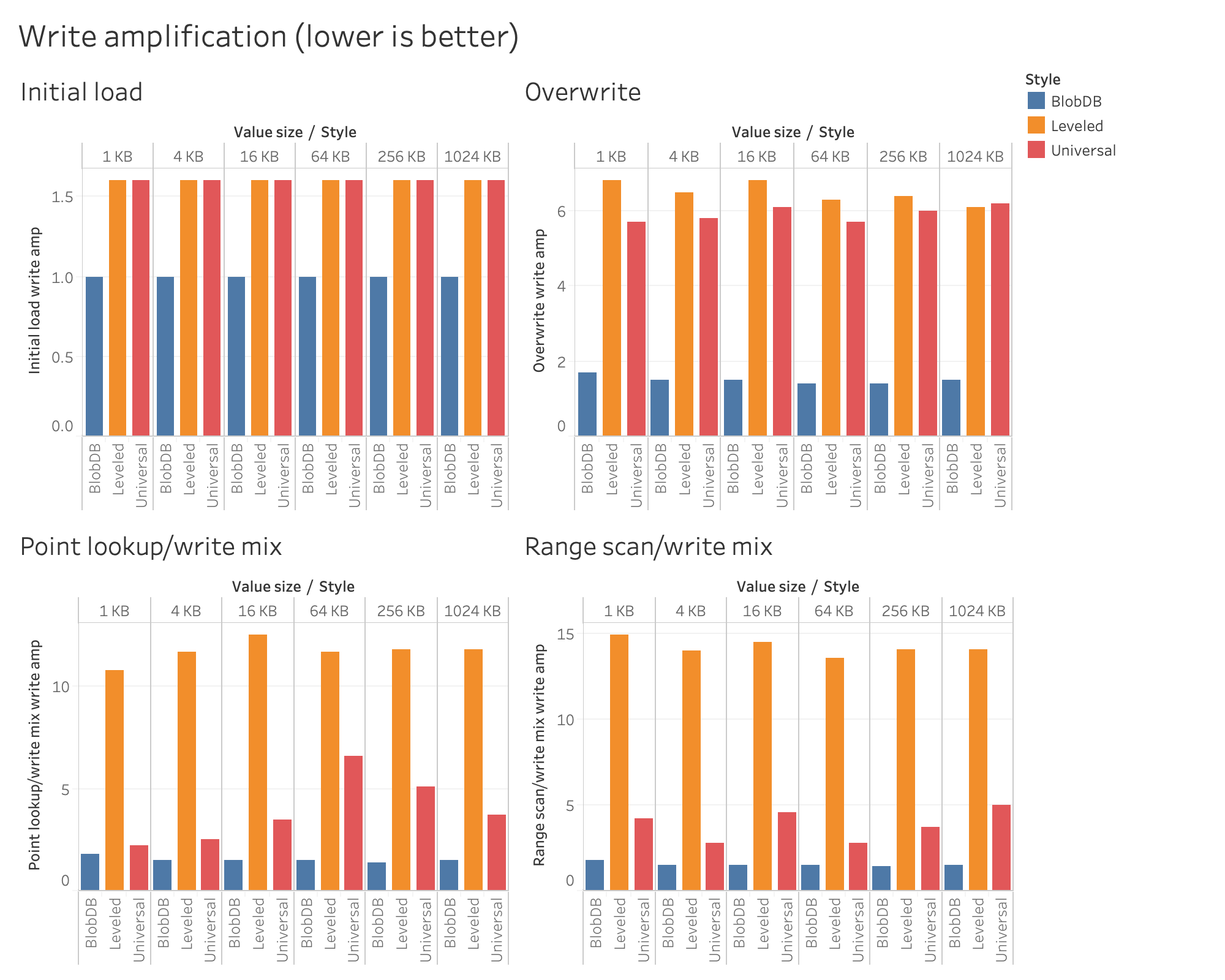
Reducing write amp is the original motivation for key-value separation. Here, we follow RocksDB’s definition of write amplification (as used in compaction statistics and the info log). That is, we define write amp as the total amount of data written by flushes and compactions divided by the amount of data written by flushes, where “data written” includes SST files and blob files as well (if applicable). The following charts show that BlobDB significantly reduces write amplification for all of our (non-read only) workloads.
For the initial load, where due to the nature of the workload both leveled and universal already have a low write amp factor of 1.6, BlobDB has a write amp close to the theoretical minimum of 1.0, namely in the 1.0..1.02 range, depending on value size. How is this possible? Well, the trick is that when key-value separation is used, the full compaction step only has to sort the keys but not the values. This results in a write amp that is about 36% lower than the already low write amp you get with either leveled or universal.
In the case of the overwrite workload, BlobDB had a write amp between 1.4 and 1.7 depending on value size. This is around 75-78% lower than the write amp of leveled compaction (6.1 to 6.8) and 70-77% lower than universal (5.7 to 6.2); for this workload, there wasn’t a huge difference between the performance of leveled and universal.
When it comes to the point lookup/write mix workload, BlobDB had a write amp between 1.4 and 1.8. This is 83-88% lower than the write amp of leveled compaction, which had values between 10.8 and 12.5. Universal fared much better than leveled under this workload, and had write amp in the 2.2..6.6 range; however, BlobDB still provided significant gains for all value sizes we tested: namely, write amp was 18-77% lower than that of universal, depending on value size.
As for the range scan/write mix workload, BlobDB again had a write amp between 1.4 and 1.8, while leveled had values between 13.6 and 14.9, and universal was between 2.8 and 5.0. In other words, BlobDB’s write amp was 88-90% lower than that of leveled, and 46-70% lower than that of universal.
Write performance
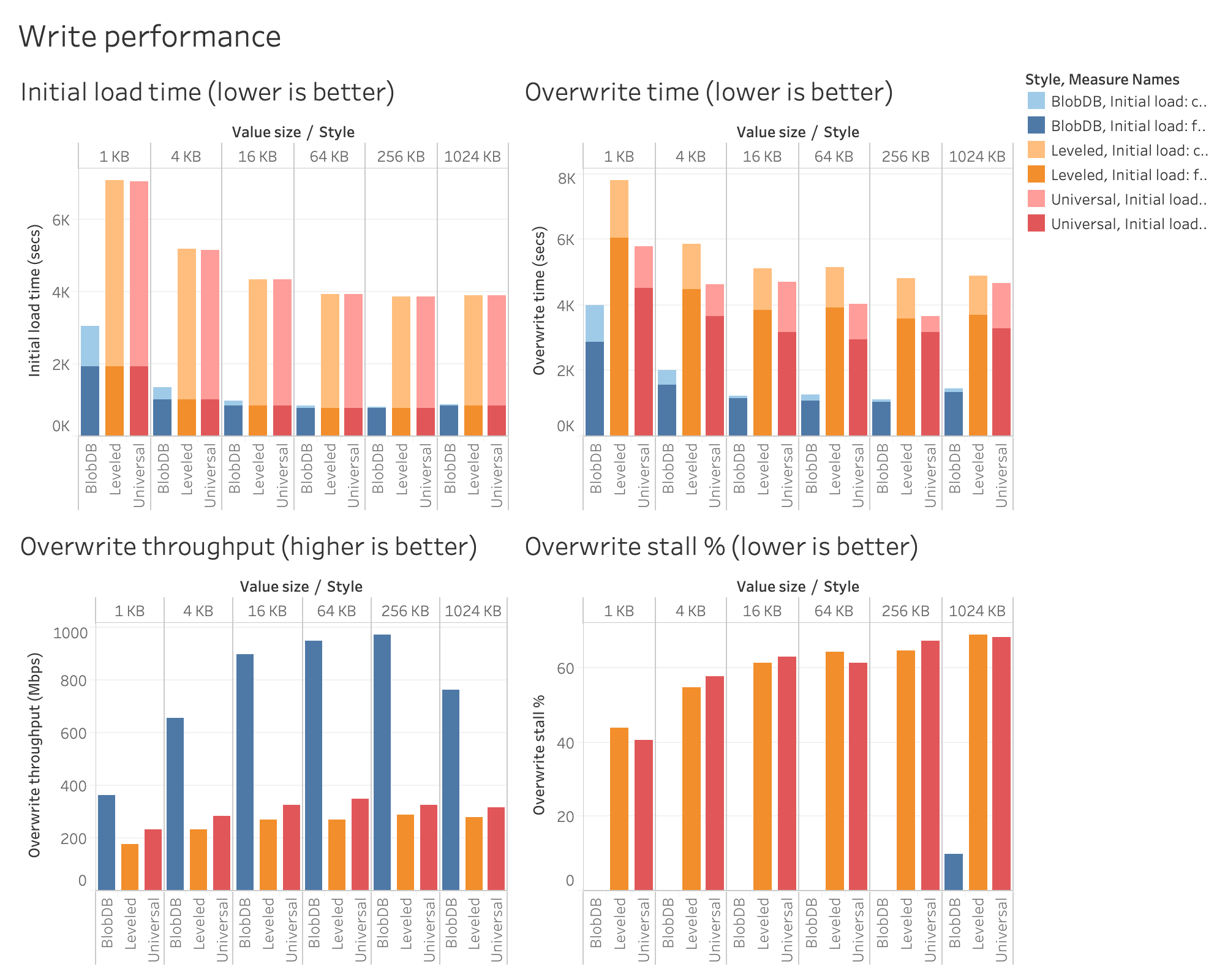
In terms of write performance, there are other factors to consider besides write amplification. The following charts show some interesting metrics for the two write-only workloads (initial load and overwrite). As discussed earlier, these two workloads perform a fixed amount of work; the two charts in the top row show how long it took BlobDB, leveled, and universal to complete that work. Note that each bar is broken down into two, corresponding to the two stages of each workload (random write and full compaction for initial load, and random write and waiting for compactions for overwrite).
For initial load, note that the random write stage takes the same amount of time regardless of which algorithm is used. This is not surprising considering the fact that compactions are disabled during this stage and thus RocksDB is simply writing L0 files (and in BlobDB’s case, blob files) as fast as it can. The second stage, on the other hand, is very different: as mentioned above, BlobDB essentially only needs to read, sort, and rewrite the keys during compaction, which can be done much much faster (with 1 MB values, more than a hundred times faster) than doing the same for large key-values. Due to this, initial load completed 2.3x to 4.7x faster overall when using BlobDB.
As for the overwrite workload, BlobDB performs much better during both stages. The two charts in the bottom row help explain why. In the case of both leveled and universal compaction, compactions can’t keep up with the write rate, which eventually leads to back pressure in the form of write stalls. As shown in the chart below, both leveled and universal stall between ~40% and ~70% of the time; on the other hand, BlobDB is stall-free except for the largest value size tested (1 MB). This naturally leads to higher throughput, namely 2.1x to 3.5x higher throughput compared to leveled, and 1.6x to 3.0x higher throughput compared to universal. The overwrite time chart also shows that the catch-up stage that waits for all compactions to finish is much shorter (and in fact, at larger value sizes, negligible) with BlobDB.
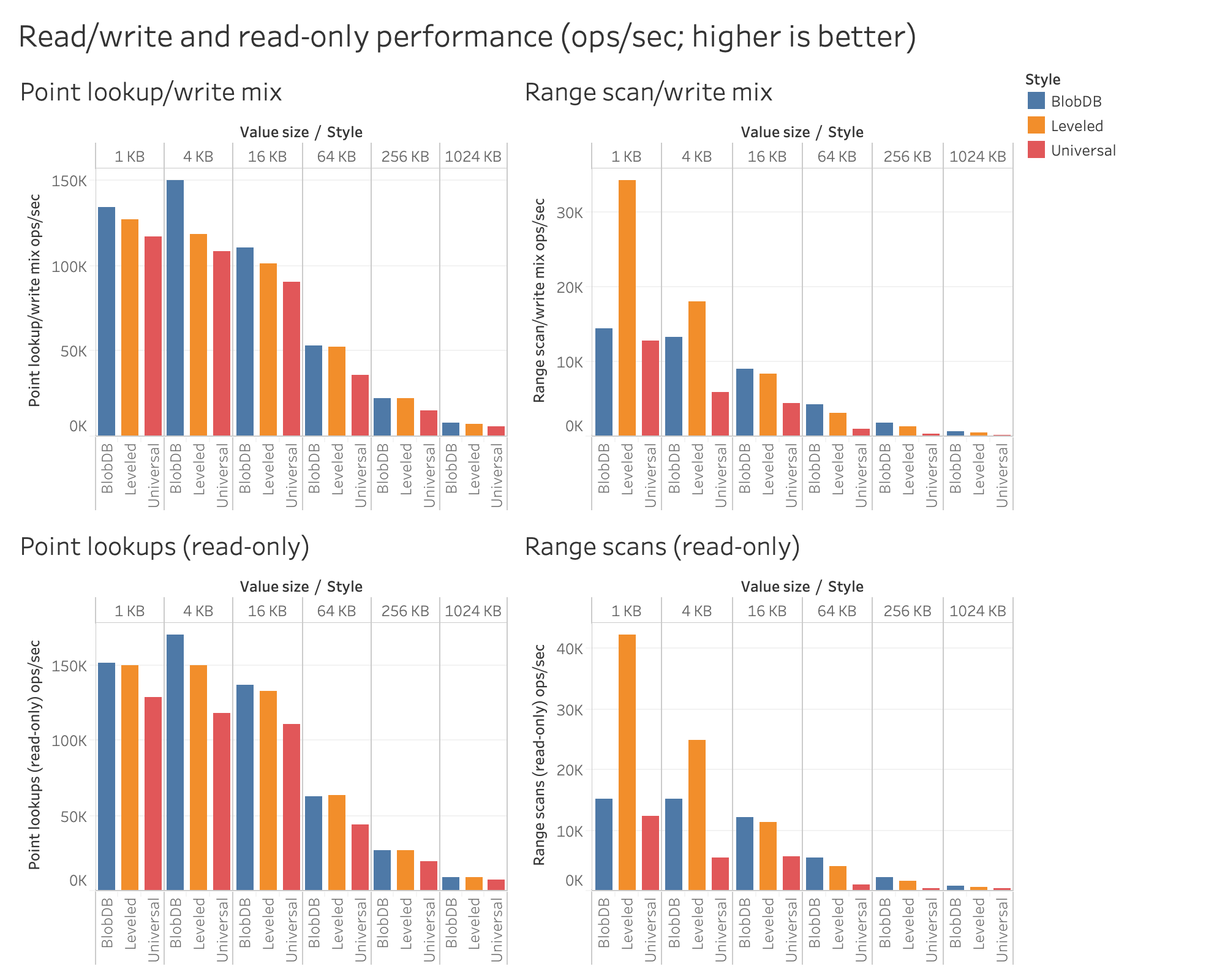
Read/write and read-only performance
The charts below show the read performance (in terms of operations per second) of BlobDB versus leveled and universal compaction under the two read/write workloads and the two read-only workloads. BlobDB meets or exceeds the read performance of leveled compaction, except for workloads involving range scans at the two smallest value sizes tested (1 KB and 4 KB). It also provides better (in some cases, much better) read performance than universal across the board. In particular, BlobDB provides up 1.4x higher read performance than leveled (for larger values), and up to 5.6x higher than universal.
Comparing the two BlobDB implementations
To compare the write performance of the new BlobDB with the legacy implementation, we ran two versions of the first (single-threaded random write) stage of the initial load benchmark using 1 KB values: one with WAL disabled, and one with WAL enabled. The new implementation completed the load 4.6x faster than the old one without WAL, and 2.3x faster with WAL.

Future work
There are a few remaining features that are not yet supported by the new BlobDB. The most important one is Merge (and the related GetMergeOperands API); in addition, we don’t currently support the EventListener interface, the GetLiveFilesMetaData and GetColumnFamilyMetaData APIs, secondary instances, and ingestion of blob files. We will continue to work on closing this gap.
We also have further plans when it comes to performance. These include optimizing garbage collection, introducing a dedicated cache for blobs, improving iterator and MultiGet performance, and evolving the blob file format amongst others.