

Per Key-Value Checksum
Summary
Silent data corruptions can severely impact RocksDB users. As a key-value library, RocksDB resides at the bottom of the user space software stack for many diverse applications. Returning wrong query results can cause unpredictable consequences for our users so must be avoided.
To prevent and detect corruption, RocksDB has several consistency checks [1], especially focusing on the storage layer. For example, SST files contain block checksums that are verified during reads, and each SST file has a full file checksum that can be verified when files are transferred.
Other sources of corruptions, such as those from faulty CPU/memory or heap corruptions, pose risks for which protections are relatively underdeveloped. Meanwhile, recent work [2] suggests one per thousand machines in our fleet will at some point experience a hardware error that is exposed to an application. Additionally, software bugs can increase the risk of heap corruptions at any time.
Hardware/heap corruptions are naturally difficult to detect in the application layer since they can compromise any data or control flow. Some factors we take into account when choosing where to add protection are the volume of data, the importance of the data, the CPU instructions that operate on the data, and the duration it resides in memory. One recently added protection, detect_filter_construct_corruption, has proven itself useful in preventing corrupt filters from being persisted. We have seen hardware encounter machine-check exceptions a few hours after we detected a corrupt filter.
The next way we intend to detect hardware and heap corruptions before they cause queries to return wrong results is through developing a new feature: per key-value checksum. This feature will eventually provide optional end-to-end integrity protection for every key-value pair. RocksDB 7.4 offers substantial coverage of the user write and recovery paths with per key-value checksum protection.
User API
For integrity protection during recovery, no change is required. Recovery is always protected.
For user write protection, RocksDB allows the user to specify per key-value protection through WriteOptions::protection_bytes_per_key or pass in protection_bytes_per_key to WriteBatch constructor when creating a WriteBatch directly. Currently, only 0 (default, no protection) and 8 bytes per key are supported. This should be fine for write batches as they do not usually contain a huge number of keys. We are working on supporting more settings as 8 bytes per key might cause considerable memory overhead when the protection is extended to memtable entries.
Feature Design
Data Structures
Protection info
For protecting key-value pairs, we chose to use a hashing algorithm, xxh3 [3], for its good efficiency without relying on special hardware. While algorithms like crc32c can guarantee detection of certain patterns of bit flips, xxh3 offers no such guarantees. This is acceptable for us as we do not expect any particular error pattern [4], and even if we did, xxh3 can achieve a collision probability close enough to zero for us by tuning the number of protection bytes per key-value.
Key-value pairs have multiple representations in RocksDB: in WriteBatch, in memtable entries and in data blocks. In this post we focus on key-values in write batches and memtable as in-memory data blocks are not yet protected.
Besides user key and value, RocksDB includes internal metadata in the per key-value checksum calculation. Depending on the representation, internal metadata consists of some combination of sequence number, operation type, and column family ID. Note that since timestamp (when enabled) is part of the user key it is protected as well.
The protection info consists of the XOR’d result of the xxh3 hash for all the protected components. This allows us to efficiently transform protection info for different representations. See below for an example converting WriteBatch protection info to memtable protection info.
A risk of using XOR is the possibility of swapping corruptions (e.g., key becomes the value and the value becomes the key). To mitigate this risk, we use an independent seed for hashing each type of component.
The following two figures illustrate how protection info in WriteBatch and memtable are calculated from a key-value’s components.
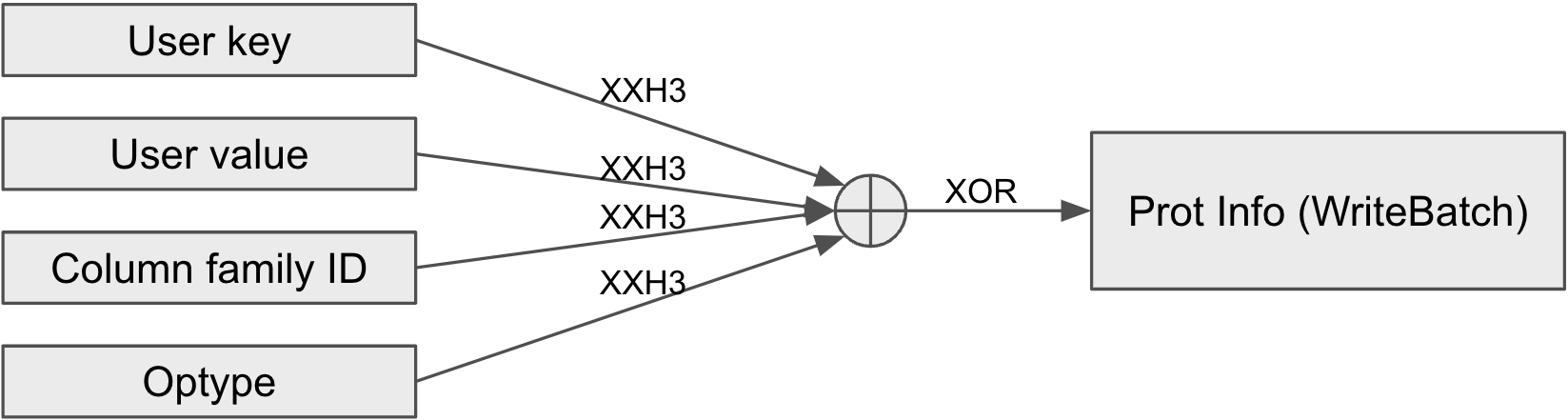
Protection info for a key-value in a WriteBatch
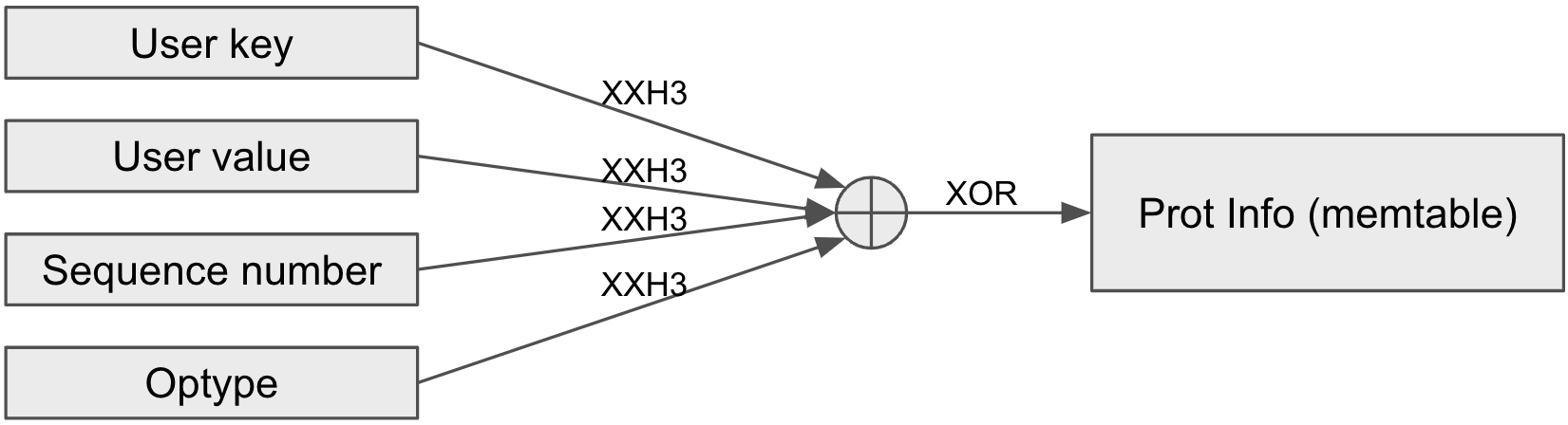
Protection info for a key-value in a memtable
The next figure illustrates how protection info for a key-value can be transformed to protect that same key-value in a different representation. Note this is done without recalculating the hash for all the key-value’s components.
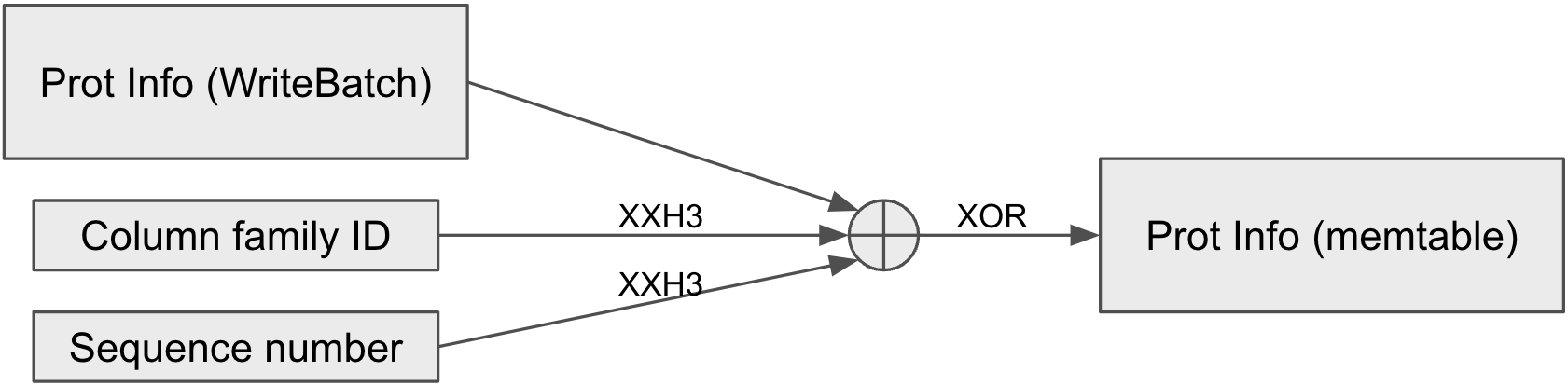
Protection info for a key-value in a memtable derived from an existing WriteBatch protection info
Above, we see two (small) components are hashed: column family ID and sequence number. When a key-value is inserted from WriteBatch into memtable, it is assigned a sequence number and drops the column family ID since each memtable is associated with one column family. Recall the xxh3 of column family ID was included in the WriteBatch protection info, which is canceled out by the column family ID xxh3 included in the XOR.
WAL fragment
WAL (Write-ahead-log) persists write batches that correspond to operations in memtables and enables consistent database recovery after restart. RocksDB writes to WAL in chunks of some fixed block size for efficiency. It is possible that some write batch does not fit into the space left in the current block and/or is larger than the fixed block size. Thus, serialized write batches (WAL records) are divided into WAL fragments before being written to WAL. The format of a WAL fragment is in the following diagram (there is another legacy format detailed in code comments). Roughly, the Type field indicates whether a fragment is at the beginning, middle or end of a record, and is used to group fragments.

Note that each fragment is prefixed by a crc32c checksum that is calculated over Type, Log # and Payload. This ensures that RocksDB can detect corruptions that happened to the WAL in the storage layer.
Write batch
As mentioned above, a WAL record is a serialized WriteBatch that is split into physical fragments during writes to WAL. During DB recovery, once a WAL record is reconstructed from one or more fragments, it is copied into the content of a WriteBatch. The write batch will then be used to restore the memtable states.
Besides the recovery path, a write batch is always constructed during user writes. Firstly, RocksDB allows users to construct a write batch directly, and pass it to DB through DB::Write() API for execution. Higher-level buffered write APIs like Transaction rely on a write batch to buffer writes prior to executing them. For unbuffered write APIs like DB::Put(), RocksDB constructs a write batch internally with the input user key and value.
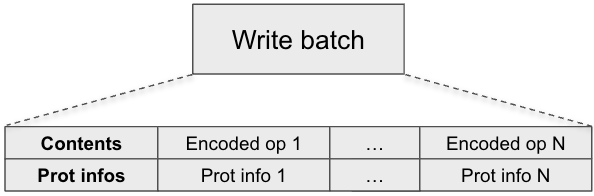
The above diagram shows a rough representation of a write batch in memory. Contents is the concatenation of serialized user operations in this write batch. Each operation consists of user key, value, op_type and optionally column family ID. With per key-value checksum protection enabled, a vector of ProtectionInfo is stored in the write batch, one for each user operation.
Memtable entry

A memtable entry is similar to write batch content, except that it captures only a single user operation and that it does not contain column family ID (since memtable is per column family). User key and value are length-prefixed, and seqno and optype are combined in a fixed 8 bytes representation.
Processes
In order to protect user writes and recovery, per key-value checksum is covered in the following code paths.
WriteBatch write
Per key-value checksum coverage starts with the user buffers that contain user key and/or value. When users call DB Write APIs (e.g., DB::Put()), or when users add operations into write batches directly (e.g. WriteBatch::Put()), RocksDB constructs ProtectionInfo from the user buffer (e.g. here) and stores the protection information within the corresponding WriteBatch object as diagramed below. Then the user key and/or value are copied into the WriteBatch, thus starting per key-value checksum protection from user buffer.
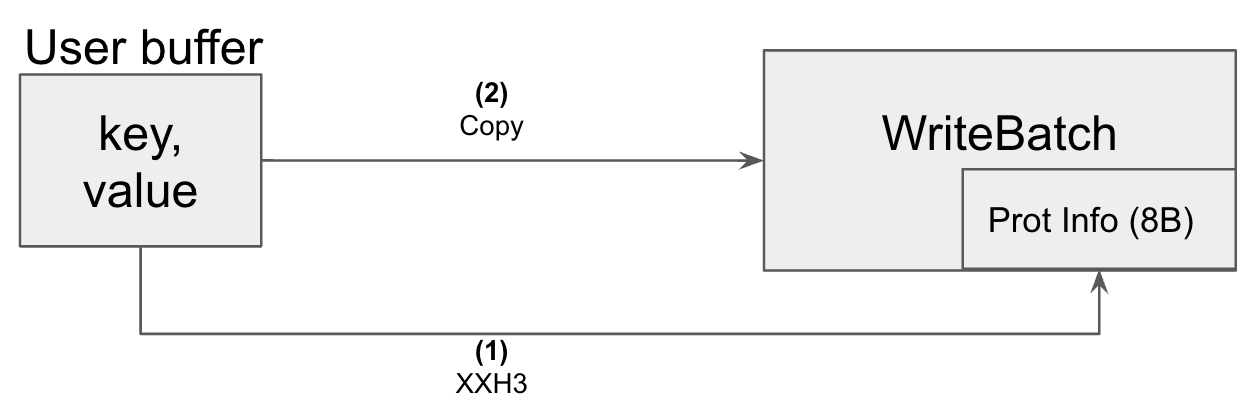
WAL write
Before a WriteBatch leaves RocksDB and be persisted in a WAL file, it is verified against its ProtectionInfo to ensure its content is not corrupted. We added WriteBatch::VerifyChecksum() for this purpose. Once we verify the content of a WriteBatch, it is then divided into potentially multiple WAL fragments and persisted in the underlying file system. From that point on, the integrity protection is handed off to the per fragment crc32c checksum that is persisted in WAL too.
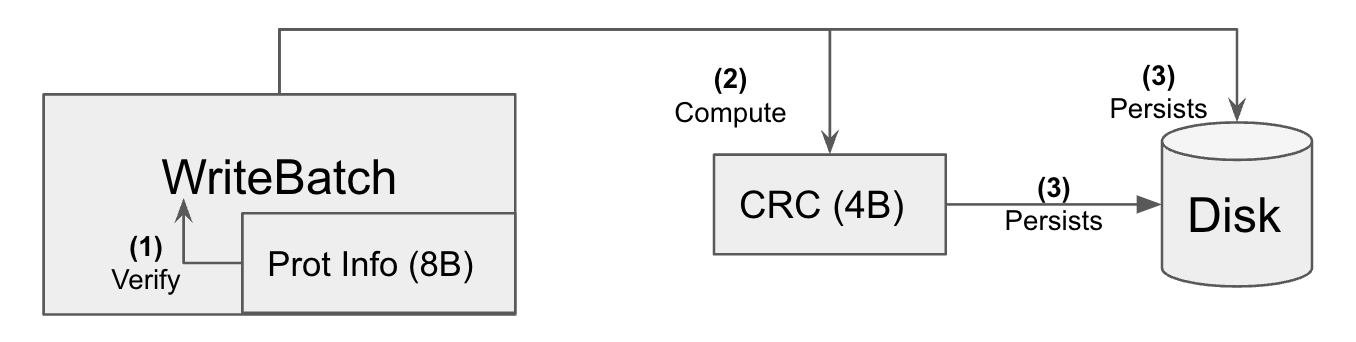
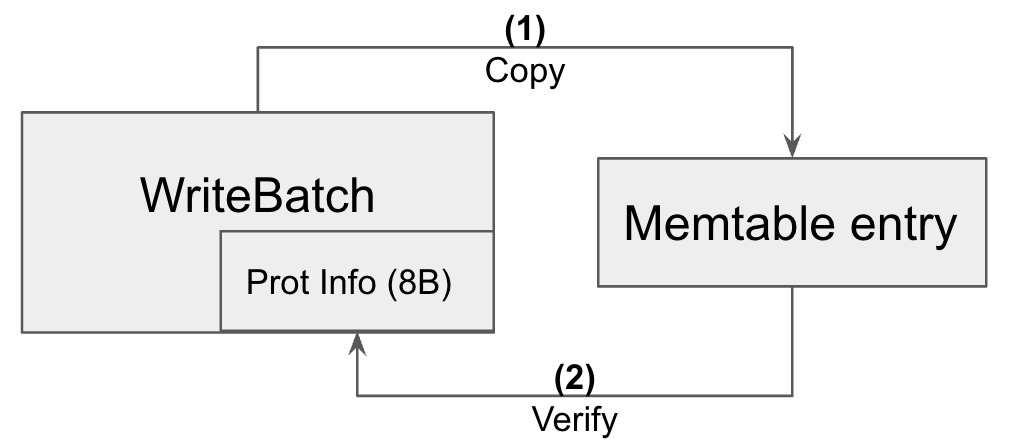
Memtable write
Similar to the WAL write path, ProtectionInfo is verified before an entry is inserted into a memtable. The difference here is that an memtable entry has its own buffer, and the content of a WriteBatch is copied into the memtable entry. So the ProtectionInfo is verified against the memtable entry buffer instead. The current per key-value checksum protection ends at this verification on the buffer containing a memtable entry, and one of the future work is to extend the coverage to key-value pairs in memtables.
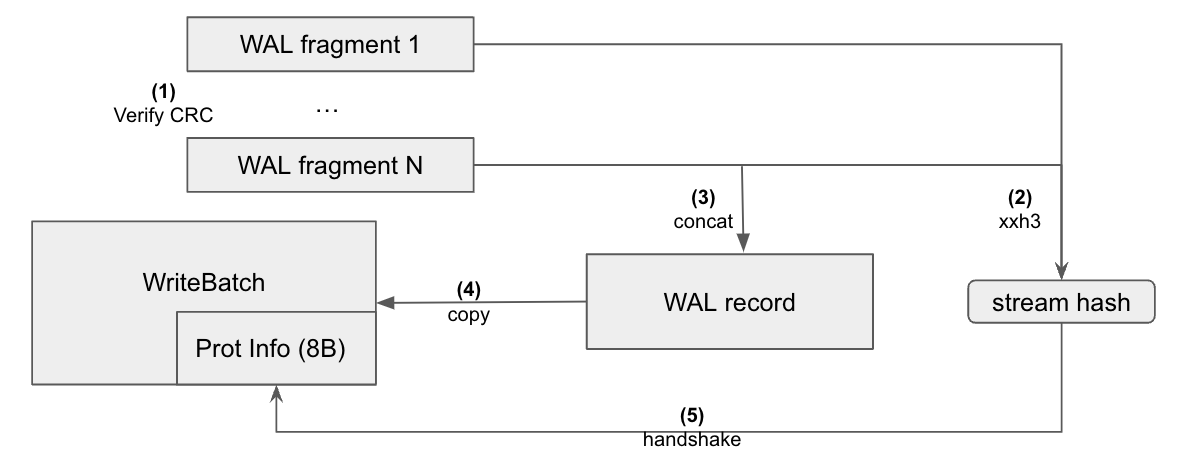
WAL read
This is for the DB recovery path: WAL fragments are read into memory, concatenated together to form WAL records, and then WriteBatches are constructed from WAL records and added to memtables. In RocksDB 7.4, once a WriteBatch copies its content from a WAL record, ProtectionInfo is constructed from the WriteBatch content and per key-value protection starts. However, this copy operation is not protected, neither is the reconstruction of a WAL record from WAL fragments. To provide protection from silent data corruption during these memory copying operations, we added checksum handshake detailed below in RocksDB 7.5.
When a WAL fragment is first read into memory, its crc32c checksum is verified. The WAL fragment is then appended to the buffer containing a WAL record. RocksDB uses xxh3’s streaming API to calculate the checksum of the WAL record and updates the streaming hash state with the new WAL fragment content whenever it is appended to the WAL record buffer (e.g. here). After the WAL record is constructed, it is copied into a WriteBatch and ProtectionInfo is constructed from the write batch content. Then, the xxh3 checksum of the WAL record is verified against the write batch content to complete the checksum handshake. If the checksum verification succeeds, then we are more confident that ProtectionInfo is calculated based on uncorrupted data, and the protection coverage continues with the newly constructed ProtectionInfo along the write code paths mentioned above.
Future work
Future coverage expansion will cover memtable KVs, flush, compaction and user reads etc.
References
[1] http://rocksdb.org/blog/2021/05/26/online-validation.html
[2] H. D. Dixit, L. Boyle, G. Vunnam, S. Pendharkar, M. Beadon, and S. Sankar, ‘Detecting silent data corruptions in the wild’. arXiv, 2022.
[3] https://github.com/Cyan4973/xxHash
[4] https://github.com/Cyan4973/xxHash/issues/229#issuecomment-511956403