Asynchronous IO in RocksDB
Summary
RocksDB provides several APIs to read KV pairs from a database, including Get and MultiGet for point lookups and Iterator for sequential scanning. These APIs may result in RocksDB reading blocks from SST files on disk storage. The types of blocks and the frequency with which they are read from storage is workload dependent. Some workloads may have a small working set and thus may be able to cache most of the data required, while others may have large working sets and have to read from disk more often. In the latter case, the latency would be much higher and throughput would be lower than the former. They would also be dependent on the characteristics of the underlying storage media, making it difficult to migrate from one medium to another, for example, local flash to disaggregated flash.
One way to mitigate the impact of storage latency is to read asynchronously and in parallel as much as possible, in order to hide IO latency. We have implemented this in RocksDB in Iterators and MultiGet. In Iterators, we prefetch data asynchronously in the background for each file being iterated on, unlike the current implementation that does prefetching synchronously, thus blocking the iterator thread. In MultiGet, we determine the set of files that a given batch of keys overlaps, and read the necessary data blocks from those files in parallel using an asynchronous file system API. These optimizations have significantly decreased the overall latency of the RocksDB MultiGet and iteration APIs on slower storage compared to local flash.
The optimizations described here are in the internal implementation of Iterator and MultiGet in RocksDB. The user API is still synchronous, so existing code can easily benefit from it. We might consider async user APIs in the future.
Design
API
A new flag in ReadOptions, async_io, controls the usage of async IO. This flag, when set, enables async IO in Iterators and MultiGet. For MultiGet, an additional ReadOptions flag, optimize_multiget_for_io (defaults to true), controls how aggressively to use async IO. If the flag is not set, files in the same level are read in parallel but not different levels. If the flag is set, the level restriction is removed and as many files as possible are read in parallel, regardless of level. The latter might have a higher CPU cost depending on the workload.
At the FileSystem layer, we use the FSRandomAccessFile::ReadAsync API to start an async read, providing a completion callback.
Scan
A RocksDB scan usually involves the allocation of a new iterator, followed by a Seek call with a target key to position the iterator, followed by multiple Next calls to iterate through the keys sequentially. Both the Seek and Next operations present opportunities to read asynchronously, thereby reducing the scan latency.
A scan usually involves iterating through keys in multiple entities - the active memtable, sealed and unflushed memtables, every L0 file, and every non-empty non-zero level. The first two are completely in memory and thus not impacted by IO latency. The latter two involve reading from SST files. This means that an increase in IO latency has a multiplier effect, since multiple L0 files and levels have to be iterated on.
Some factors, such as block cache and prefix bloom filters, can reduce the number of files to iterate and number of reads from the files. Nevertheless, even a few reads from disk can dominate the overall latency. RocksDB uses async IO in both Seek and Next to mitigate the latency impact, as described below.
Seek
A RocksDB iterator maintains a collection of child iterators, one for each L0 file and for each non-empty non-zero levels. For a Seek operation every child iterator has to Seek to the target key. This is normally done serially, by doing synchronous reads from SST files when the required data blocks are not in cache. When the async_io option is enabled, RocksDB performs the Seek in 2 phases - 1) Locate the data block required for Seek in each file/level and issue an async read, and 2) in the second phase, reseek with the same key, which will wait for the async read to finish at each level and position the table iterator. Phase 1 reads multiple blocks in parallel, reducing overall Seek latency.
Next
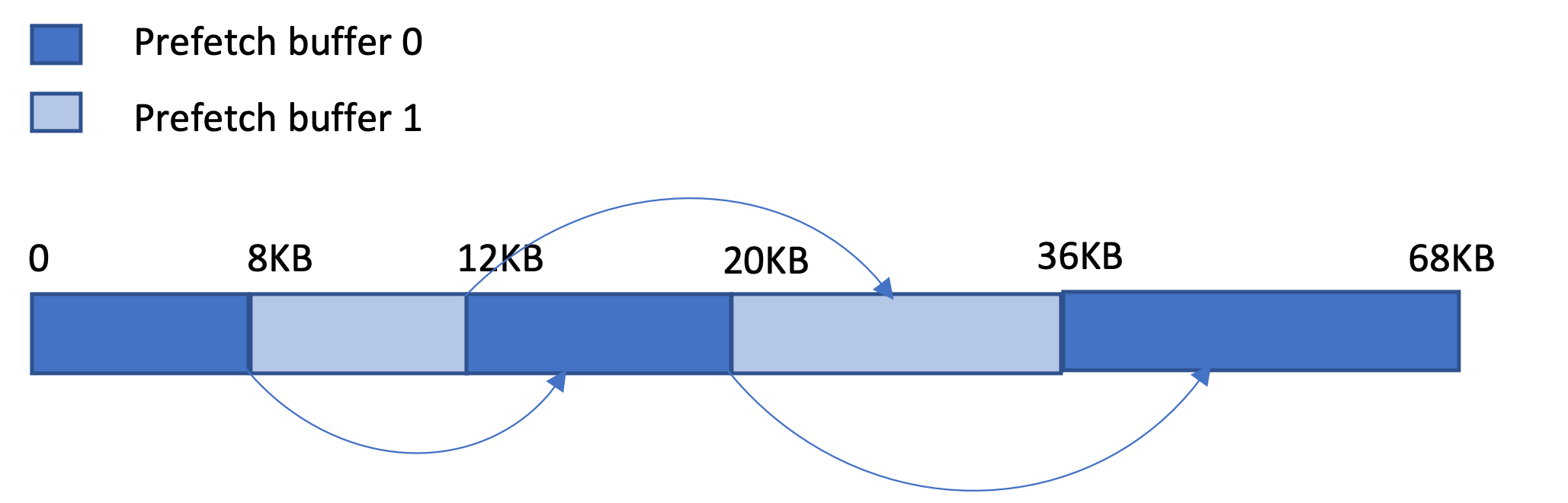
For the iterator Next operation, RocksDB tries to reduce the latency due to IO by prefetching data from the file. This prefetching occurs when a data block required by Next is not present in the cache. The reads from file and prefetching is managed by the FilePrefetchBuffer, which is an object that’s created per table iterator (BlockBasedTableIterator). The FilePrefetchBuffer reads the required data block, and an additional amount of data that varies depending on the options provided by the user in ReadOptions and BlockBasedTableOptions. The default behavior is to start prefetching on the third read from a file, with an initial prefetch size of 8KB and doubling it on every subsequent read, upto a max of 256KB.
While the prefetching in the previous paragraph helps, it is still synchronous and contributes to the iterator latency. When the async_io option is enabled, RocksDB prefetches in the background, i.e while the iterator is scanning KV pairs. This is accomplished in FilePrefetchBuffer by maintaining two prefetch buffers. The prefetch size is calculated as usual, but its then split across the two buffers. As the iteration proceeds and data in the first buffer is consumed, the buffer is cleared and an async read is scheduled to prefetch additional data. This read continues in the background while the iterator continues to process data in the second buffer. At this point, the roles of the two buffers are reversed. This does not completely hide the IO latency, since the iterator would have to wait for an async read to complete after the data in memory has been consumed. However, it does hide some of it by overlapping CPU and IO, and async prefetch can be happening on multiple levels in parallel, further reducing the latency.
MultiGet
The MultiGet API accepts a batch of keys as input. Its a more efficient way of looking up multiple keys compared to a loop of Gets. One way MultiGet is more efficient is by reading multiple data blocks from an SST file in a batch, for keys in the same file. This greatly reduces the latency of the request, compared to a loop of Gets. The MultiRead FileSystem API is used to read a batch of data blocks.
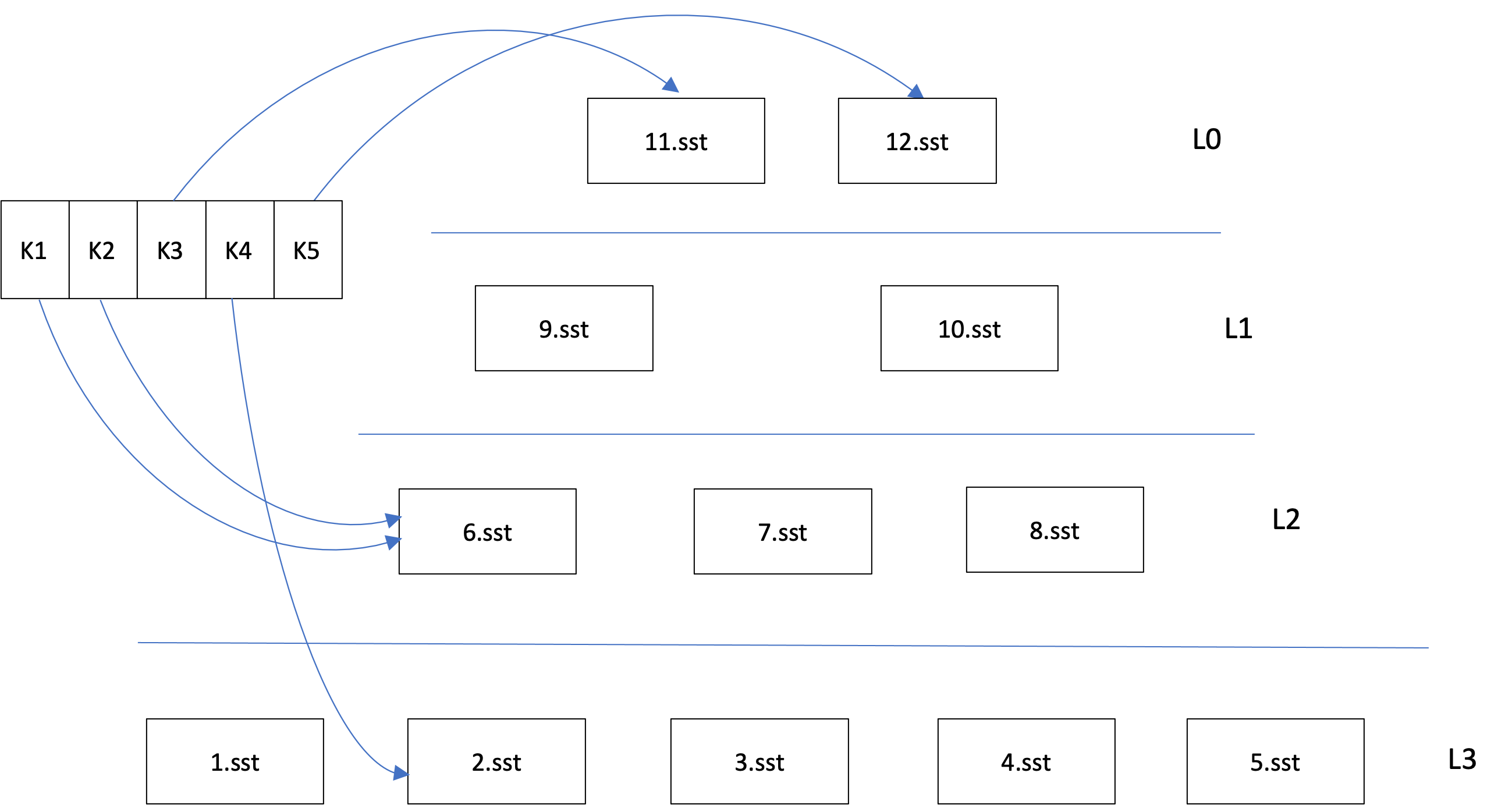
Even with the MultiRead optimization, subset of keys that are in different files still need to be read serially. We can take this one step further and read multiple files in parallel. In order to do this, a few fundamental changes were required in the MultiGet implementation -
- Coroutines - A MultiGet involves determining the set of keys in a batch that overlap an SST file, and then calling TableReader::MultiGet to do the actual lookup. The TableReader probes the bloom filter, traverses the index block, looks up the block cache for the necessary, reads the missing data blocks from the SST file, and then searches for the keys in the data blocks. There is a significant amount of context that’s accumulated at each stage, and it would be rather complex to interleave data blocks reads by multiple TableReaders. In order to simplify it, we used async IO with C++ coroutines. The TableReader::MultiGet is implemented as a coroutine, and the coroutine is suspended after issuing async reads for missing data blocks. This allows the top-level MultiGet to iterate through the TableReaders for all the keys, before waiting for the reads to finish and resuming the coroutines.
- Filtering - The downside of using coroutines is the CPU overhead, which is non-trivial. To minimize the overhead, its desirable to not use coroutines as much as possible. One scenario in which we can completely avoid the call to a TableReader::MultiGet coroutine is if we know that none of the overlapping keys are actually present in the SST file. This can easily determined by probing the bloom filter. In the previous implementation, the bloom filter lookup was embedded in TableReader::MultiGet. However, we could easily implement is as a separate step, before calling TableReader::MultiGet.
- Splitting batches - The default strategy of MultiGet is to lookup keys in one level (or L0 file), before moving on to the next. This limits the amount of IO parallelism we can exploit. For example, the keys in a batch may not be clustered together, and may be scattered over multiple files. Even if they are clustered together in the key space, they may not all be in the same level. In order to optimize for these situations, we determine the subset of keys that are likely to be in a given level, and then split the MultiGet batch into 2 - the subset in that level, and the remainder. The batch containing the remainder can then be processed in parallel. The subset of keys likely to be in a level is determined by the filtering step.
Together, these changes enabled two types of latency optimization in MultiGet using async IO - single-level and multi-level. The former reads data blocks in parallel from multiple files in the same LSM level, while the latter reads in parallel from multiple files in multiple levels.
Results
Command used to generate the database:
buck-out/opt/gen/rocks/tools/rocks_db_bench —db=/rocks_db_team/prefix_scan —env_uri=ws://ws.flash.ftw3preprod1 -logtostderr=false -benchmarks="fillseqdeterministic" -key_size=32 -value_size=512 -num=5000000 -num_levels=4 -multiread_batched=true -use_direct_reads=false -adaptive_readahead=true -threads=1 -cache_size=10485760000 -async_io=false -multiread_stride=40000 -disable_auto_compactions=true -compaction_style=1 -bloom_bits=10
Structure of the database:
Level[0]: /000233.sst(size: 24828520 bytes)
Level[0]: /000232.sst(size: 49874113 bytes)
Level[0]: /000231.sst(size: 100243447 bytes)
Level[0]: /000230.sst(size: 201507232 bytes)
Level[1]: /000224.sst - /000229.sst(total size: 405046844 bytes)
Level[2]: /000211.sst - /000223.sst(total size: 814190051 bytes)
Level[3]: /000188.sst - /000210.sst(total size: 1515327216 bytes)
MultiGet
MultiGet benchmark command:
buck-out/opt/gen/rocks/tools/rocks_db_bench -use_existing_db=true —db=/rocks_db_team/prefix_scan -benchmarks="multireadrandom" -key_size=32 -value_size=512 -num=5000000 -batch_size=8 -multiread_batched=true -use_direct_reads=false -duration=60 -ops_between_duration_checks=1 -readonly=true -threads=4 -cache_size=300000000 -async_io=true -multiread_stride=40000 -statistics —env_uri=ws://ws.flash.ftw3preprod1 -logtostderr=false -adaptive_readahead=true -bloom_bits=10
Single-file
The default MultiGet implementation of reading from one file at a time had a latency of 1292 micros/op.
multireadrandom : 1291.992 micros/op 3095 ops/sec 60.007 seconds 185768 operations; 1.6 MB/s (46768 of 46768 found)
rocksdb.db.multiget.micros P50 : 9664.419795 P95 : 20757.097056 P99 : 29329.444444 P100 : 46162.000000 COUNT : 23221 SUM : 239839394
Single-level
MultiGet with async_io=true and optimize_multiget_for_io=false had a latency of 775 micros/op.
multireadrandom : 774.587 micros/op 5163 ops/sec 60.009 seconds 309864 operations; 2.7 MB/s (77816 of 77816 found)
rocksdb.db.multiget.micros P50 : [6029.601964](tel:6029601964) P95 : 10727.467932 P99 : 13986.683940 P100 : 47466.000000 COUNT : 38733 SUM : 239750172
Multi-level
With all optimizations turned on, MultiGet had the lowest latency of 508 micros/op.
multireadrandom : 507.533 micros/op 7881 ops/sec 60.003 seconds 472896 operations; 4.1 MB/s (117536 of 117536 found)
rocksdb.db.multiget.micros P50 : 3923.819467 P95 : 7356.182075 P99 : 10880.728723 P100 : 28511.000000 COUNT : 59112 SUM : 239642721
Scan
Benchmark command:
buck-out/opt/gen/rocks/tools/rocks_db_bench -use_existing_db=true —db=/rocks_db_team/prefix_scan -benchmarks="seekrandom" -key_size=32 -value_size=512 -num=5000000 -batch_size=8 -multiread_batched=true -use_direct_reads=false -duration=60 -ops_between_duration_checks=1 -readonly=true -threads=4 -cache_size=300000000 -async_io=true -multiread_stride=40000 -statistics —env_uri=ws://ws.flash.ftw3preprod1 -logtostderr=false -adaptive_readahead=true -bloom_bits=10 -seek_nexts=65536
With async scan
seekrandom : 414442.303 micros/op 9 ops/sec 60.288 seconds 581 operations; 326.2 MB/s (145 of 145 found)
Without async scan
seekrandom : 848858.669 micros/op 4 ops/sec 60.529 seconds 284 operations; 158.1 MB/s (74 of 74 found)
Known Limitations
These optimizations apply only to block based table SSTs. File system support for the ReadAsync and Poll interfaces is required. Currently, it is available only for PosixFileSystem.
The MultiGet async IO optimization has a few additional limitations -
- Depends on folly, which introduces a few additional build steps
- Higher CPU overhead due to coroutines. The CPU overhead of MultiGet may increase 6-15%, with the worst case being a single threaded MultiGet batch of keys with 1 key/file intersection and 100% cache hit rate. A more realistic case of multiple threads with a few keys (~4) overlap per file should see ~6% higher CPU util.
- No parallelization of metadata reads. A metadata read will block the thread.
- A few other cases will also be in serial, such as additional block reads for merge operands.