
Reduce Write Amplification by Aligning Compaction Output File Boundaries
TL;DR
By cutting the compaction output file earlier and allowing larger than targeted_file_size to align the compaction output files to the next level files, it can reduce WA (Write Amplification) by more than 10%. The feature is enabled by default after the user upgrades RocksDB to version 7.8.0+.
Background
RocksDB level compaction picks one file from the source level and compacts to the next level, which is a typical partial merge compaction algorithm. Compared to the full merge compaction strategy for example universal compaction, it has the benefits of smaller compaction size, better parallelism, etc. But it also has a larger write amplification (typically 20-30 times user data). One of the problems is wasted compaction at the beginning and ending:
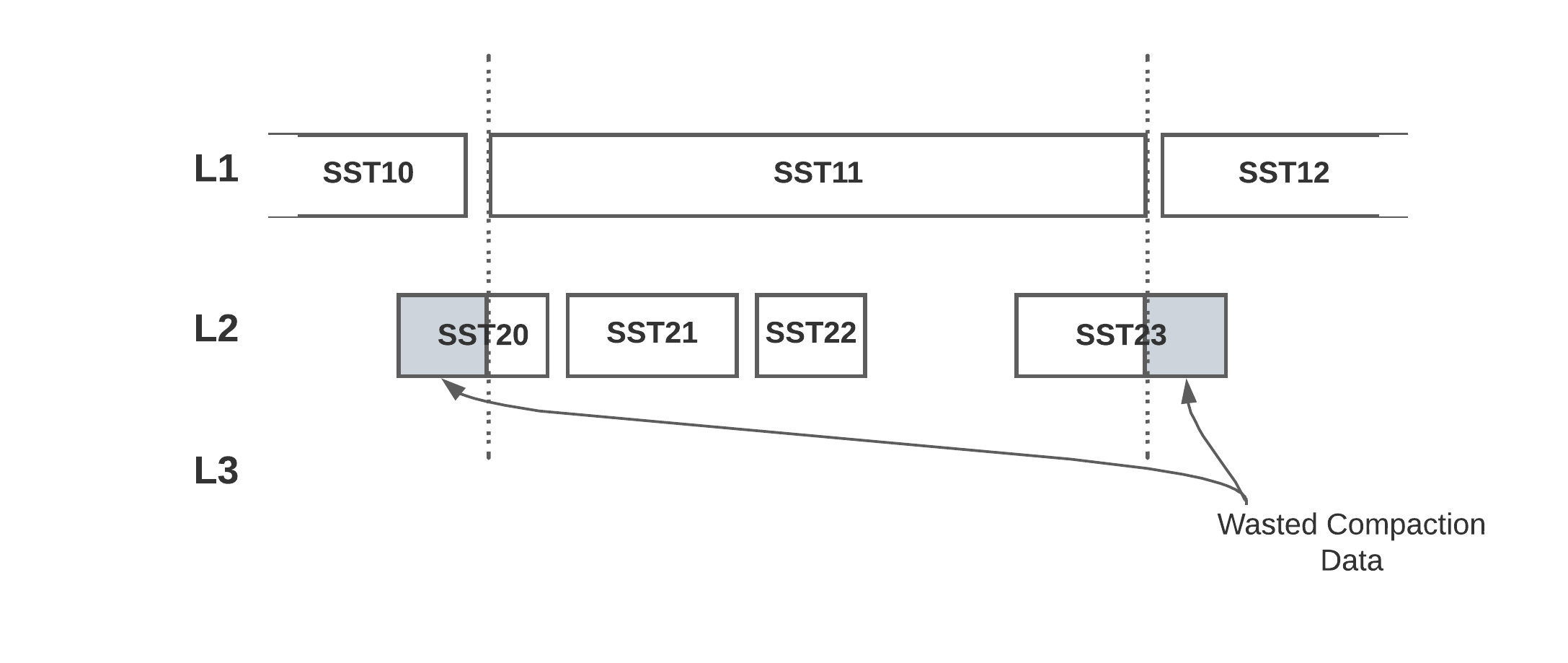
In the diagram above, SST11 is selected for the compaction, it overlaps with SST20 to SST23, so all these files are selected for compaction. But the beginning and ending of the SST on Level 2 are wasted, which also means it will be compacted again when SST10 is compacting down. If the file boundaries are aligned, then the wasted compaction size could be reduced. On average, the wasted compaction is 1 file size: 0.5 at the beginning, and 0.5 at the end. Typically the average compaction fan-out is about 6 (with the default max_bytes_for_level_multiplier = 10), then 1 / (6 + 1) ~= 14% of compaction is wasted.
implementation
To reduce such wasted compaction, RocksDB now tries to align the compaction output file to the next level’s file. So future compactions will have fewer wasted compaction. For example, the above case might be cut like this:
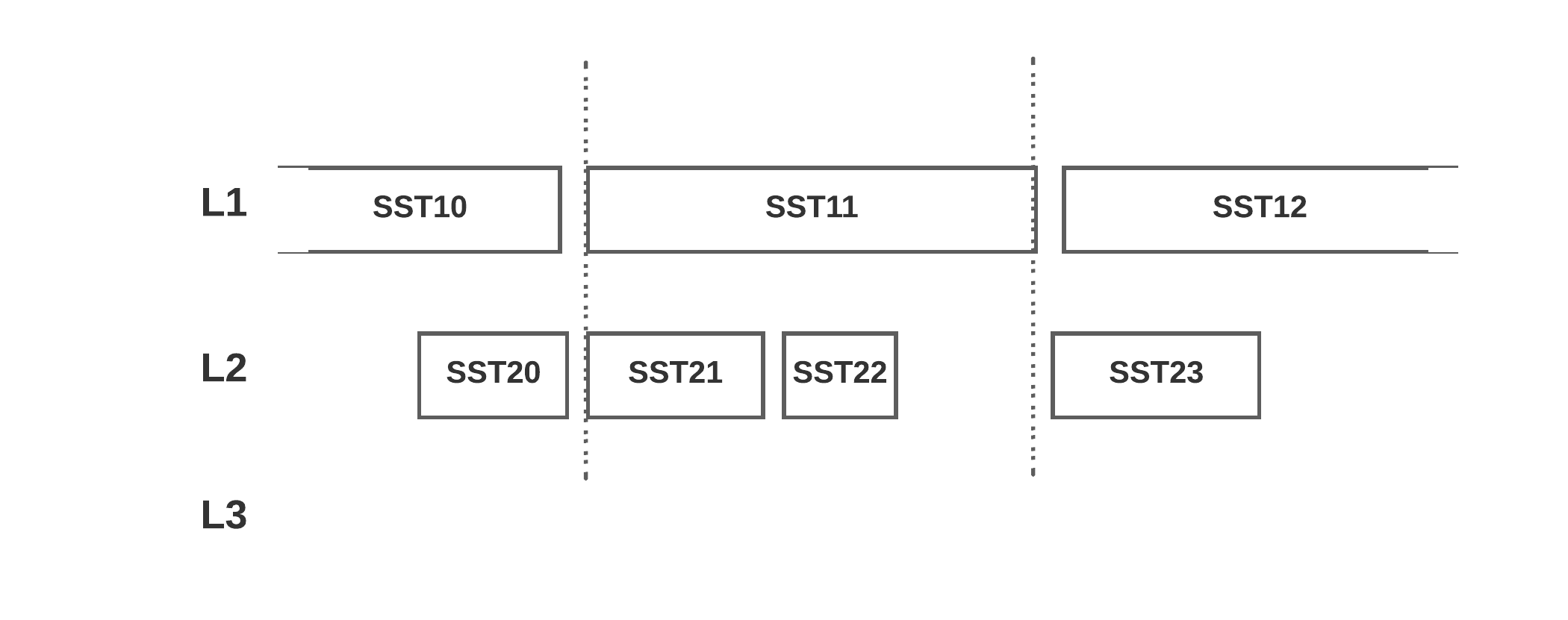
The trade-off is the file won’t be cut exactly after it exceeds target_file_size_base, instead, it will be more likely cut when it’s aligned with the next level file’s boundary, so the file size might be more varied. It could be as small as 50% of target_file_size or as large as 2x target_file_size. It will only impact non-bottommost-level files, which should be only ~11% of the data.
Internally, RocksDB tries to cut the file so its size is close to the target_file_size setting but also aligned with the next level boundary. When the compaction output file hit a next-level file boundary, either the beginning or ending boundary, it will cut if:
1
current_size > ((5 * min(bounderies_num, 8) + 50) / 100) * target_file_size
(details)
The file size is also capped at 2x target_file_size: details.
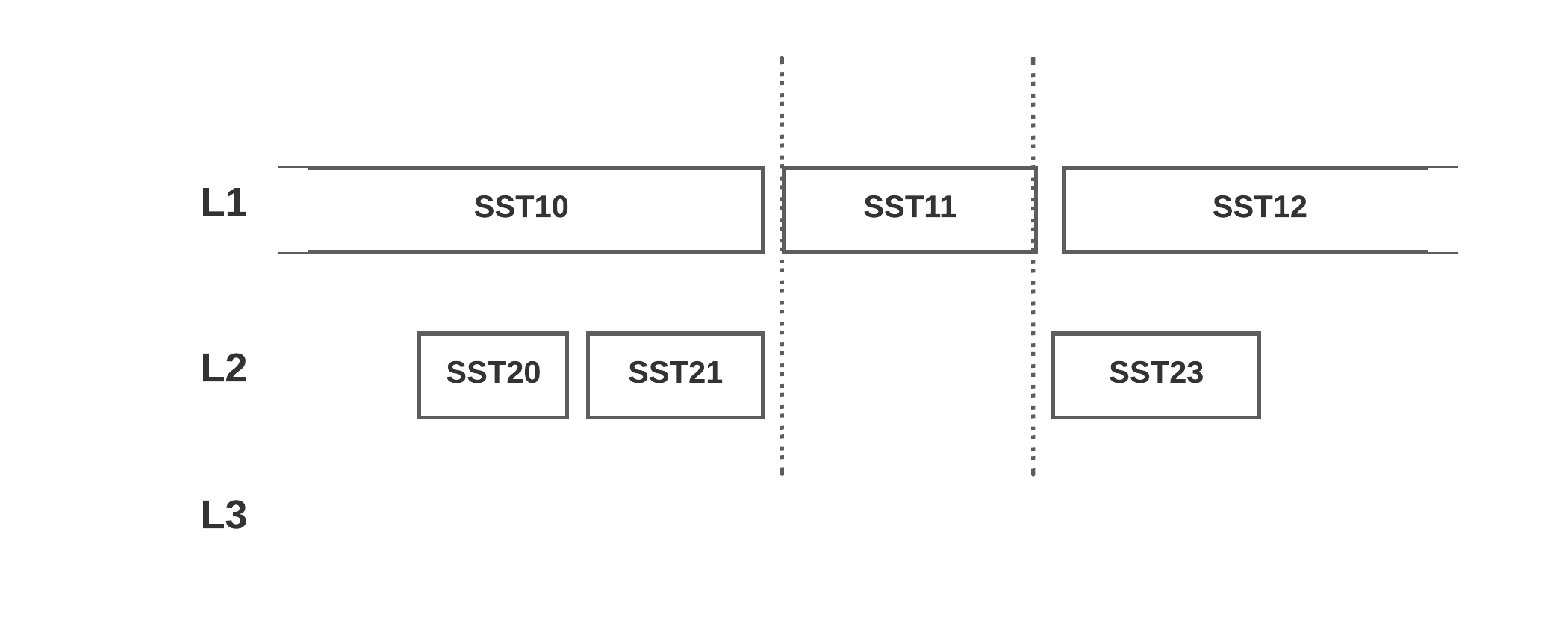
Another benefit of cutting the file earlier is having more trivial move compaction, which is moving the file from a high level to a low level without compacting anything. Based on a compaction simulator test, the trivial move data is increased by 30% (but still less than 1% compaction data is trivial move):
Based on the db_bench test, it can save ~12% compaction load, here is the test command and result:
1
2
3
4
5
6
7
8
9
TEST_TMPDIR=/data/dbbench ./db_bench --benchmarks=fillrandom,readrandom -max_background_jobs=12 -num=400000000 -target_file_size_base=33554432
# baseline:
Flush(GB): cumulative 25.882, interval 7.216
Cumulative compaction: 285.90 GB write, 162.36 MB/s write, 269.68 GB read, 153.15 MB/s read, 2926.7 seconds
# with this change:
Flush(GB): cumulative 25.882, interval 7.753
Cumulative compaction: 249.97 GB write, 141.96 MB/s write, 233.74 GB read, 132.74 MB/s read, 2534.9 seconds
The feature is enabled by default by upgrading to RocksDB 7.8 or later versions, as the feature should have a limited impact on the file size and have great write amplification improvements. If in a rare case, it needs to opt out, set
1
options.level_compaction_dynamic_file_size = false;
Other Options and Benchmark
We also tested a few other options, starting with a fixed threshold: 75% of the target_file_size and 50%. Then with a dynamic threshold that is explained, but still limiting file size smaller than the target_file_size.
- Baseline (main branch before PR#10655);
- Fixed Threshold
75%: after 75% of target file size, cut the file whenever it aligns with a low level file boundary; - Fixed Threshold
50%: reduce the threshold to 50% of target file size; - Dynamic Threshold
(5*bounderies_num + 50)percent of target file size and maxed at 90%; - Dynamic Threshold + allow 2x the target file size (chosen option).
Test Environment and Data
To speed up the benchmark, we introduced a compaction simulator within Rocksdb (details), which replaced the physical SST with in-memory data (a large bitset). Which can test compaction more consistently. As it’s a simulator, it has its limitations:
it assumes each key-value has the same size;
- no deletion (but has override);
- doesn’t consider data compression;
- single-threaded and finish all compactions before the next flush (so no write stall).
We use 3 kinds of the dataset for tests:
- Random Data, has an override, evenly distributed;
- Zipf distribution with alpha = 1.01, moderately skewed;
- Zipf distribution with alpha = 1.2, highly skewed.
Write Amplification
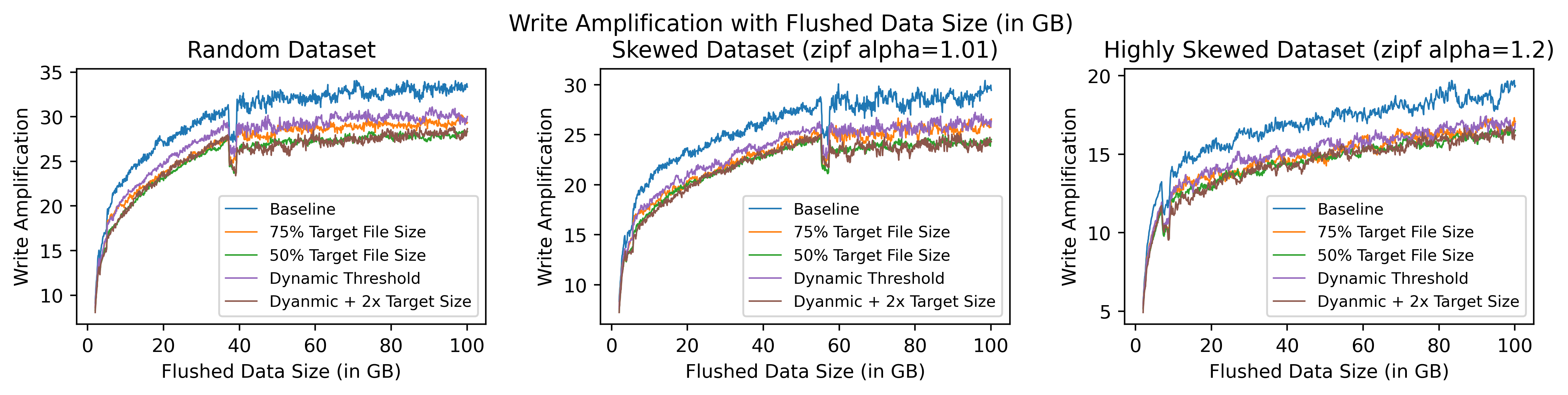
As we can see, all options are better than the baseline. Option5 (brown) and option3 (green) have similar WA improvements. (The sudden WA drop during ~40G Random Dataset is because we enabled level_compaction_dynamic_level_bytes and the level number was increased from 3 to 4, the similar test result without enabling level_compaction_dynamic_level_bytes).
File Size Distribution at the End of Test
This is the file size distribution at the end of the test, which loads about 100G data. As this change only impacts the non-bottommost file size, and the majority of the SST files are bottommost, there’re no significant differences:
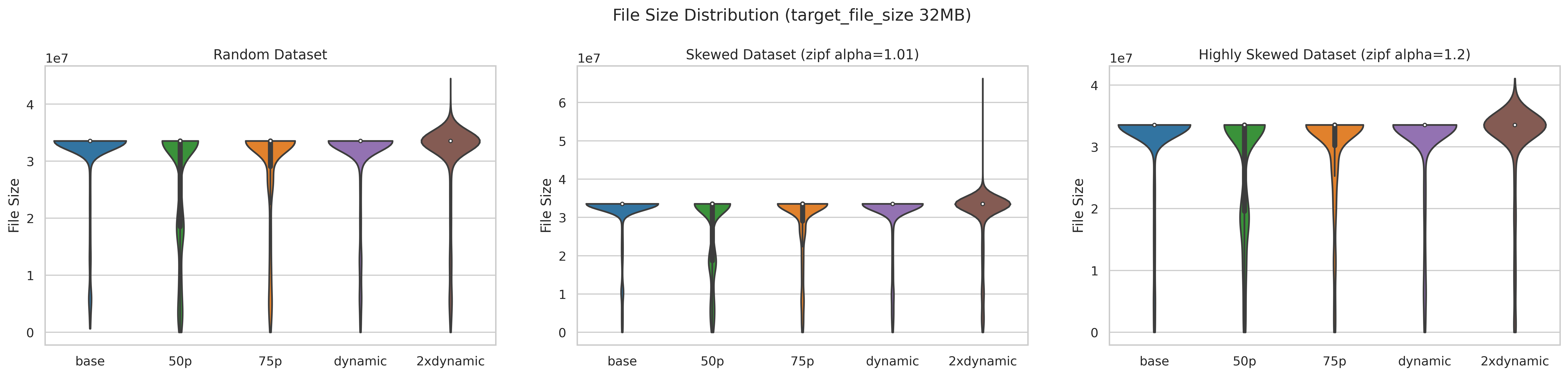
All Compaction Generated File Sizes
The high-level files are much more likely to be compacted, so all compaction-generated files size has more significant change:
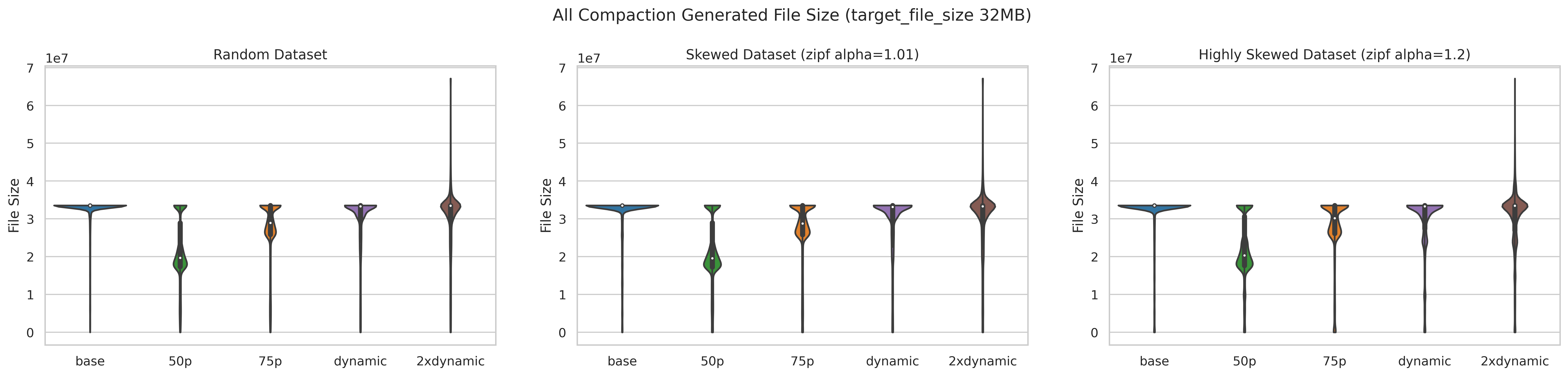
Overall option5 has most of the file size close to the target file size. vs. option3 has a much smaller size. Here are more detailed stats for compaction output file size:
1
2
3
4
base 50p 75p dynamic 2xdynamic
count 1.656000e+03 1.960000e+03 1.770000e+03 1.687000e+03 1.705000e+03
mean 3.116062e+07 2.634125e+07 2.917876e+07 3.060135e+07 3.028076e+07
std 7.145242e+06 1.065134e+07 8.800474e+06 7.612939e+06 8.046139e+06
Summary
Allowing more dynamic file size and aligning the compaction output file to the next level file’s boundary improves the RocksDB write amplification by more than 10%, which will be enabled by default in 7.8.0 release. We picked a simple algorithm to decide when to cut the output file, which can be further improved. For example, by estimating output file size with index information. Any suggestions or PR are welcomed.
Acknowledgements
We thank Siying Dong for initializing the file-cutting idea and thank Andrew Kryczka, Mark Callaghan for contributing to the ideas. And Changyu Bi for the detailed code review.