
Time-Aware Tiered Storage in RocksDB
TL:DR
Tiered storage is now natively supported in the RocksDB with the option last_level_temperature, time-aware Tiered storage feature guarantees the recently written data are put in the hot tier storage with the option preclude_last_level_data_seconds.
Background
RocksDB Tiered Storage assigns a data temperature when creating the new SST which hints the file system to put the data on the corresponding storage media, so the data in a single DB instance can be placed on different storage media. Before the feature, the user typically creates multiple DB instances for different storage media, for example, one DB instance stores the recent hot data and migrates the data to another cold DB instance when the data becomes cold. Tracking and migrating the data could be challenging. With the RocksDB tiered storage feature, RocksDB compaction migrates the data from hot storage to cold storage.
Currently, RocksDB supports assigning the last level file temperature. In an LSM tree, typically the last level data is most likely the coldest. As the most recent data is on the higher level and gradually compacted to the lower level. The higher level data is more likely to be read, because:
- RocksDB read always queries from the higher level to the lower level until it finds the data;
- The high-level data is much more likely to be read and written by the compactions.
Problem
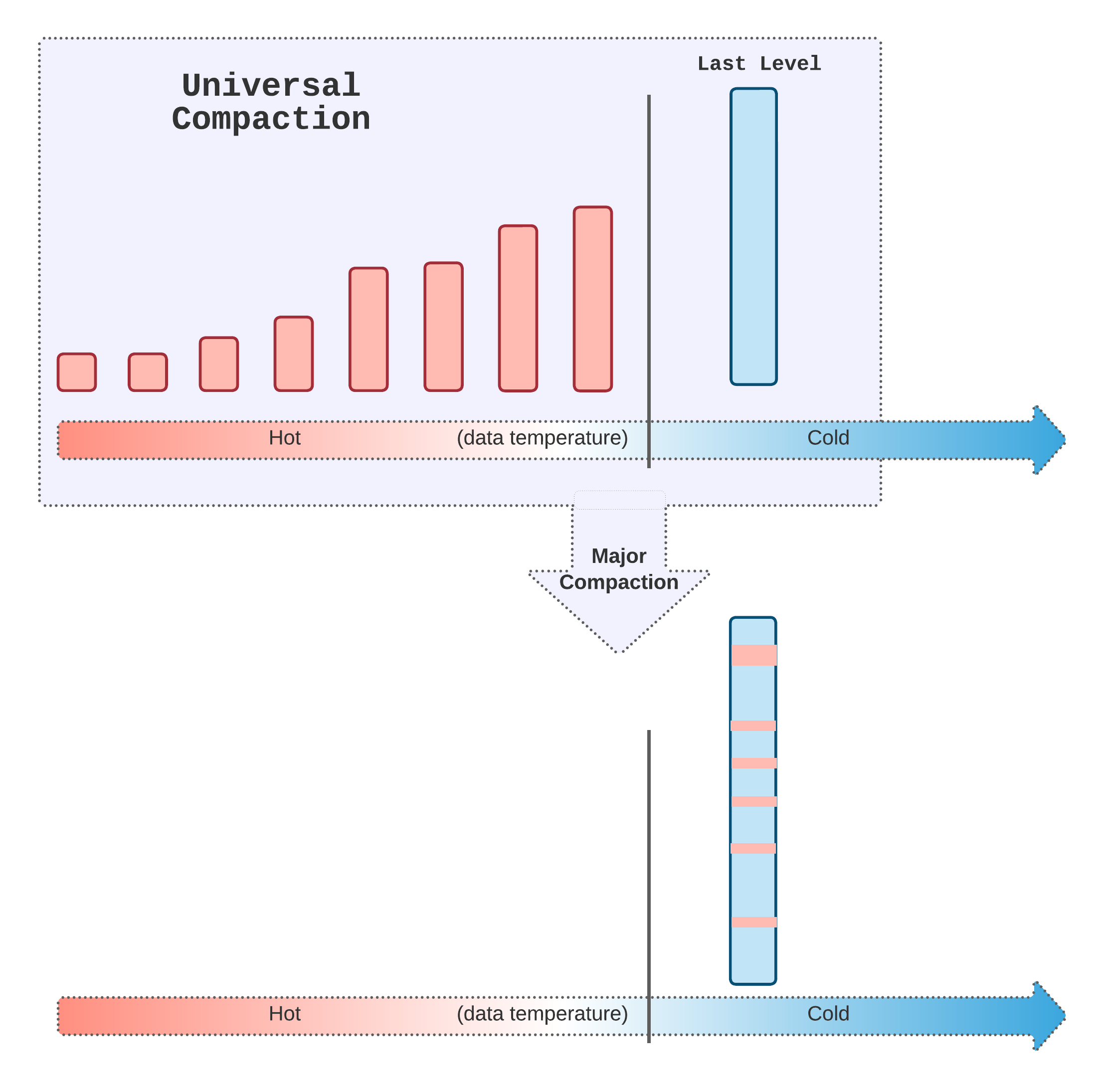
Generally in the LSM tree, hotter data is likely on the higher levels as mentioned before, but it is not always the case, for example for the skewed dataset, the recent data could be compacted to the last level first. For the universal compaction, a major compaction would compact all data to the last level (the cold tier) which includes both recent data that should be cataloged as hot data. In production, we found the majority of the compaction load is actually major compaction (more than 80%).
Goal and Non-goals
It’s hard to predict the hot and cold data. The most frequently accessed data should be cataloged as hot data. But it is hard to predict which key is going to be accessed most, it is also hard to track the per-key based access history. The time-aware tiered storage feature is only focusing on the use cases that the more recent data is more likely to be accessed. Which is the majority of the cases, but not all.
User APIs
Here are the 3 main tiered storage options:
1
2
3
Temperature last_level_temperature = Temperature::kUnknown;
uint64_t preclude_last_level_data_seconds = 0;
uint64_t preserve_internal_time_seconds = 0;
last_level_temperature defines the data temperature for the last level SST files, which is typically kCold or kWarm. RocksDB doesn’t check the option value, instead it just passes that to the file_system API with FileOptions.temperature when creating the last level SST files. For all the other files, non-last-level SST files, and non-SST files like manifest files, the temperature is set to kUnknown, which typically maps to hot data.
The user can also get each SST’s temperature information through APIs:
1
2
3
db.GetLiveFilesStorageInfo();
db.GetLiveFilesMetaData();
db.GetColumnFamilyMetaData();
User Metrics
Here are the tiered storage related statistics:
1
2
3
4
5
6
7
8
9
10
11
HOT_FILE_READ_BYTES,
WARM_FILE_READ_BYTES,
COLD_FILE_READ_BYTES,
HOT_FILE_READ_COUNT,
WARM_FILE_READ_COUNT,
COLD_FILE_READ_COUNT,
// Last level and non-last level statistics
LAST_LEVEL_READ_BYTES,
LAST_LEVEL_READ_COUNT,
NON_LAST_LEVEL_READ_BYTES,
NON_LAST_LEVEL_READ_COUNT,
And more details from IOStats:
1
2
3
4
5
6
7
8
9
10
11
12
13
struct FileIOByTemperature {
// the number of bytes read to Temperature::kHot file
uint64_t hot_file_bytes_read;
// the number of bytes read to Temperature::kWarm file
uint64_t warm_file_bytes_read;
// the number of bytes read to Temperature::kCold file
uint64_t cold_file_bytes_read;
// total number of reads to Temperature::kHot file
uint64_t hot_file_read_count;
// total number of reads to Temperature::kWarm file
uint64_t warm_file_read_count;
// total number of reads to Temperature::kCold file
uint64_t cold_file_read_count;
Implementation
There are 2 main components for this feature. One is the time-tracking, and another is the per-key based placement compaction. These 2 components are relatively independent and linked together during the compaction initialization phase which gets the sequence number for splitting the hot and cold data. The time-tracking components can even be enabled independently by setting the option preserve_internal_time_seconds. The purpose of that is before migrating existing user cases to the tiered storage feature and avoid compacting the existing hot data to the cold tier (detailed in the migration session below).
Unlike the user-defined timestamp feature, the time tracking feature doesn’t have accurate time information for each key. It only samples the time information and gives a rough estimation for the key write time. Here is the high-level graph for the implementation:
Time Tracking
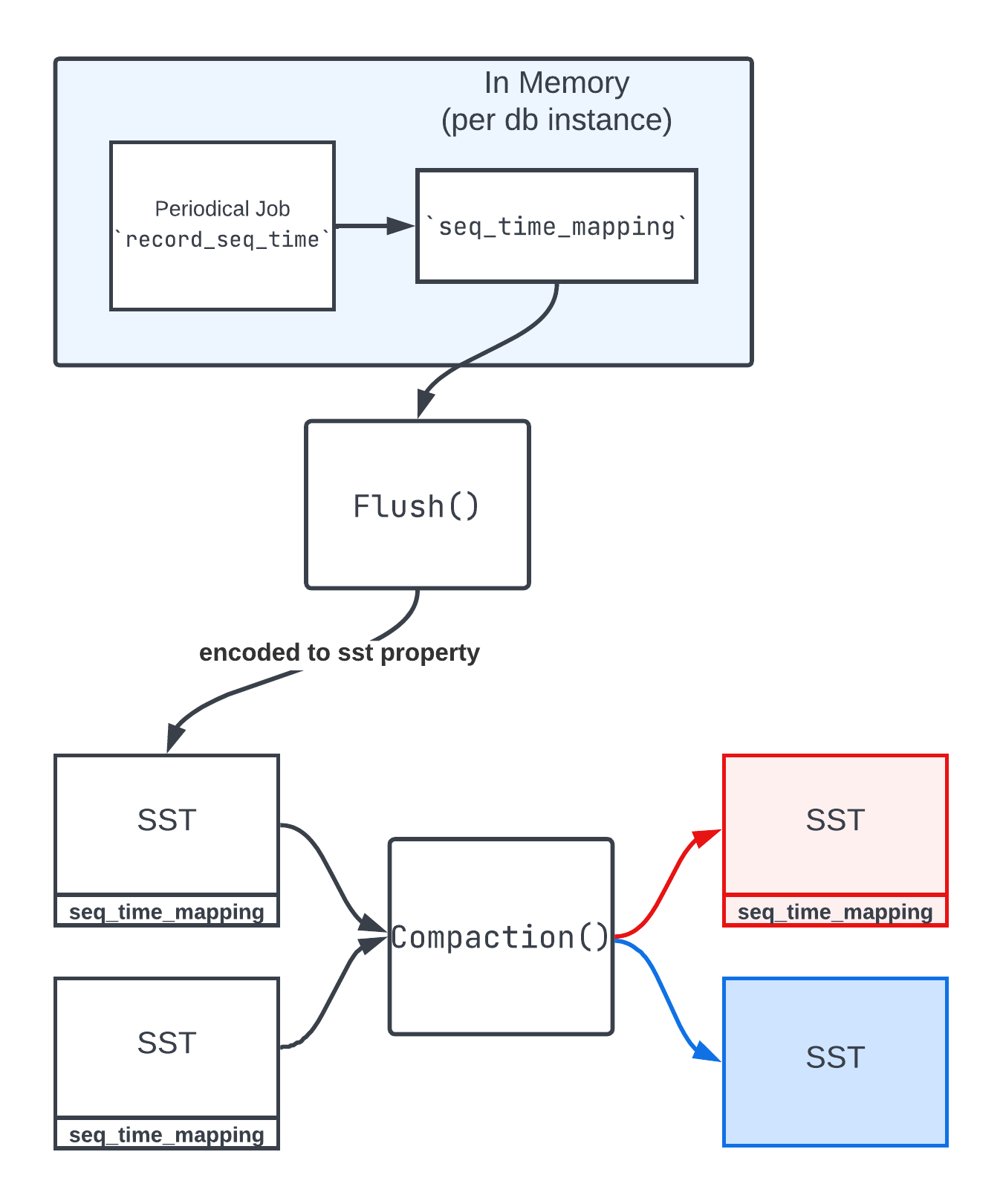
Time tracking information is recorded by a periodic task which gets the latest sequence number and the current time and then stores it in an in-memory data structure. The interval of the periodic task is determined by the user setting preserve_internal_time_seconds and dividing that by 100. For example, if 3 days of data should be precluded from the last level, then the interval of the periodic task is about 0.7 hours (3 * 24 / 100 ~= 0.72), which also means only the latest 100 seq->time pairs needed in memory.
Currently, the in-memory seq_time_mapping is only used during Flush() and encoded to the SST property. The data is delta encoded and again maximum 100 pairs are stored, so the extra data size is pretty small (far less than 1KB per SST) and only non-last-level SSTs need to have that information. Internally, RocksDB also uses the minimal sequence number and SST creation time from the SST metadata to improve the time accuracy. The sequence number to time information is distributed in each SST, ranging from the min seqno to max seqno for that SST file, so each SST has its self-contained time information. This also means there could be redundancy for the time information, for example, if 2 SSTs have an overlapped sequence number (which is very likely for non-L0 files), the same seq->time pair may exist in both SSTs. For the future, the time information could also be useful for other potential features like a better estimate of the oldest timestamp for an SST which is critical for the RocksDB TTL feature.
Per-Key Placement Compaction
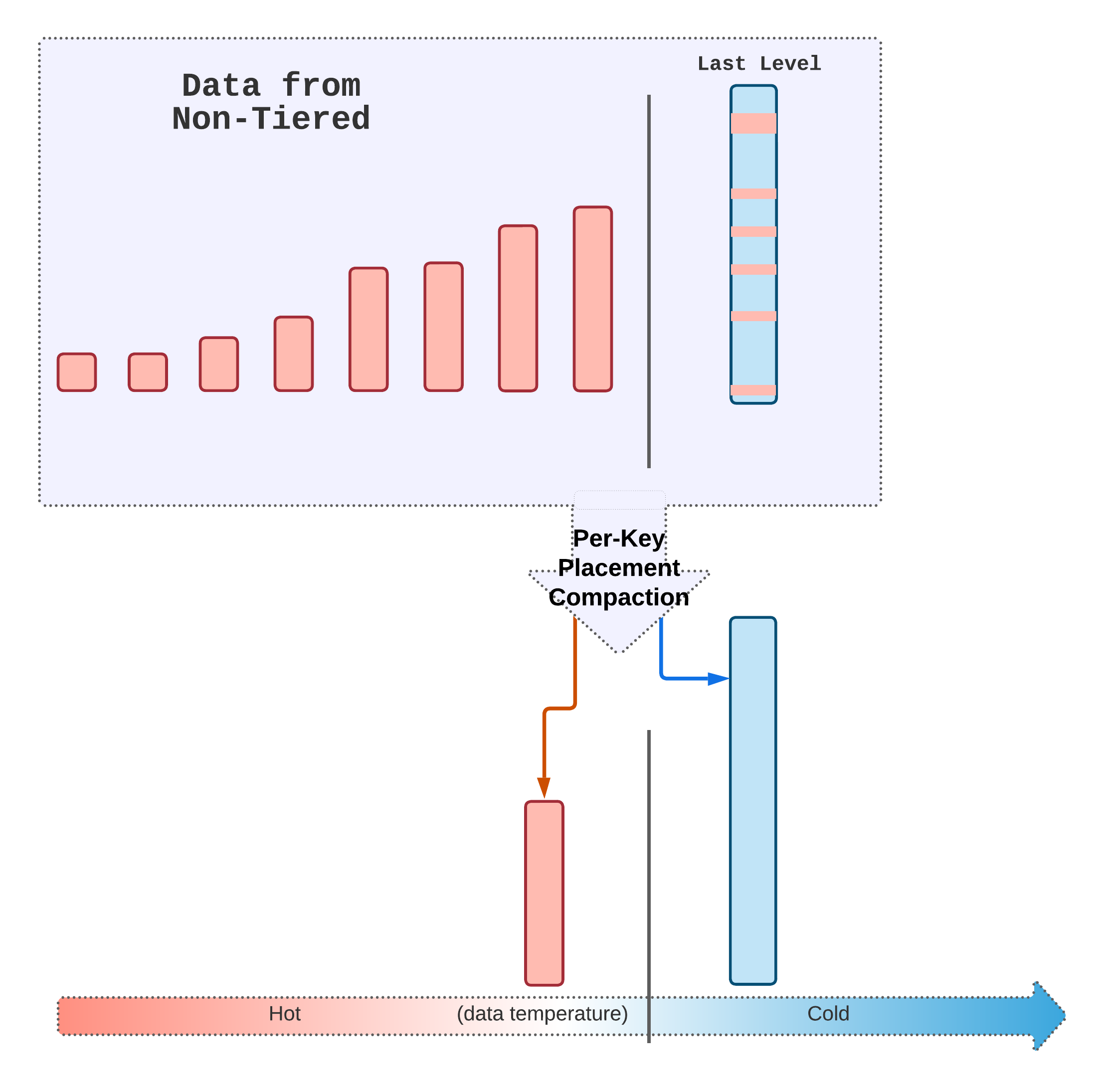
Compare to normal compaction which only outputs the data to a single level, Per-key placement compaction can output data to 2 different levels, as per-per placement compaction is only for the last level compaction, so the 2 output levels would always be the penultimate level, and the last level. The compaction places the key to its corresponding tier by simply checking the key’s sequence number.
At the beginning of the compaction, the compaction job collects all seq to time information from every input SSTs and merges them together, then based on the current time to get the oldest sequence number that should be put into non-last-level (hot tier). During the last level compaction, as long as the key is newer than the oldest_sequence_number, it will be placed in the penultimate level (hot tier) instead of the last level (cold tier).
Note, RocksDB also places the keys that are within the user snapshot in the hot tier, there’re a few reasons for that:
- It’s reasonable to assume snapshot-protected data are hot data;
- Avoid mixing the sequence number not zeroed out data with old last-level data, which is desirable to reduce the oldest obsolete data time (it’s defined as the oldest SST time that has a non-zero sequence number). It also means tombstones are always placed in the hot tier, which is also desirable as it should be pretty small.
- The original motivation was to avoid moving data from the lower level to a higher level in case the user increases the
preclude_last_level_data_seconds, so the snapshot-protected data in the last level will become hot again, and moving data to a higher level. It’s not always safe to move data from a lower level to a higher level in the LSM tree which could cause key conflict. Later we added a conflict check to allow the data to move up as long as there’s no key conflict, but then the movement is not guaranteed (see Migration for details)
Migration
Once the user enables the feature, it enables both time tracking and per-key placement compaction at the same time. As the existing data, it can still be mismarked as cold data. To have a smooth migration to the feature. The user can enable the time-tracking feature first. For example, if the user plans to set preclude_last_level_data_seconds to 3 days, the user can enable time tracking 3 days earlier with preserve_internal_time_seconds. Then when enabling the tiered storage feature, it already has the time information for the last 3 days’ hot data, then per-key placement compaction won’t compact them to the last level.
Just preserving the time information won’t prevent the data from compacting to the last level (which should be still on the hot tier). Once the preclude_last_level_data_seconds and last_level_temperature features are enabled, some of the last-level data might need to move up. Currently, RocksDB just does a conflict check, the hot/cold split in this case is not guaranteed.
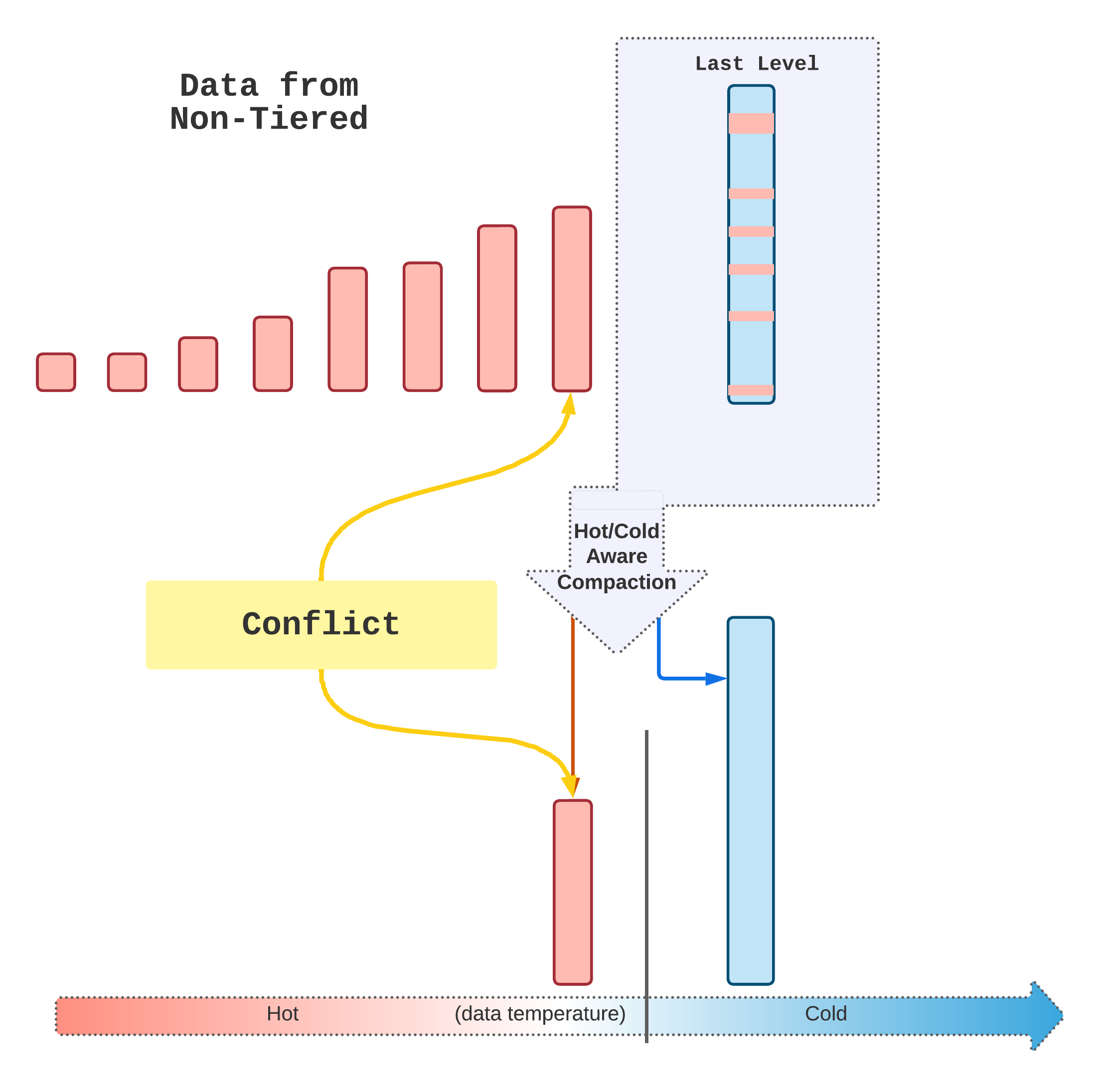
Summary
Time-aware tired storage feature guarantees the new data is placed in the hot tier, which is ideal for the tiering use cases where the most recent data is likely the hot data. It’s done by tracking the write time information and per-key placement compaction to split the hot/cold data.
The tiered storage feature is actively being developed, any suggestions or PRs will be welcomed.
Acknowledgements
We thank Siying Dong and Andrew Kryczka for brainstorming and reviewing the feature design and implementation. And it was my fortune to work with the RocksDB team members!