Java Foreign Function Interface
Java Foreign Function Interface (FFI)
Evolved Binary has been working on several aspects of how the Java API to RocksDB can be improved. The recently introduced FFI features in Java provide significant opportunities for improving the API. We have investigated this through a prototype implementation.
Java 19 introduced a new FFI Preview which is described as an API by which Java programs can interoperate with code and data outside of the Java runtime. By efficiently invoking foreign functions (i.e., code outside the JVM), and by safely accessing foreign memory (i.e., memory not managed by the JVM), the API enables Java programs to call native libraries and process native data without the brittleness and danger of JNI.
If the twin promises of efficiency and safety are realised, then using FFI as a mechanism to support a future RocksDB API may be of significant benefit.
- Remove the complexity of
JNIaccess toC++ RocksDB - Improve RocksDB Java API performance
- Reduce the opportunity for coding errors in the RocksDB Java API
Here’s what we did. We have
- created a prototype FFI branch
- updated the RocksDB Java build to use Java 19
- implemented an
FFI Preview APIversion of core RocksDB feature (get()) - Extended the current JMH benchmarks to also benchmark the new FFI methods. Usefully, JNI and FFI can co-exist peacefully, so we use the existing RocksDB Java to do support work around the FFI-based
get()implementation.
Implementation
How JNI Works
JNI requires a preprocessing step during build/compilation to generate header files which are linked into by Pure Java code. C++ implementations of the methods in the headers are implemented. Corresponding native methods are declared in Java and the whole is linked together.
Code in the C++ methods uses what amounts to a JNI library to access Java values and objects and to create Java objects in response.
How FFI Works
FFI provides the facility for Java to call existing native (in our case C++) code from Pure Java without having to generate support files during compilation steps. FFI does support an external tool (jextract) which makes generating common boilerplate easier and less error prone, but we choose to start prototyping without it, in part better to understand how things really work.
FFI does its job by providing 2 things
- A model for allocating, reading and writing native memory and native structures within that memory
- A model for discovering and calling native methods with parameters consisting of native memory references and/or values
The called C++ is invoked entirely natively. It does not have to access any Java objects to retrieve data it needs. Therefore existing packages in C++ and other sufficiently low level languages can be called from Java without having to implement stubs in the C++.
Our Approach
While we could in principle avoid writing any C++, C++ objects and classes are not easily defined in the FFI model, so to begin with it is easier to write some very simple C-like methods/stubs in C++ which can immediately call into the object-oriented core of RocksDB. We define structures with which to pass parameters to and receive results from the C-like method(s) we implement.
C++ Side
The first method we implement is
extern "C" int rocksdb_ffi_get_pinnable(
ROCKSDB_NAMESPACE::DB* db, ROCKSDB_NAMESPACE::ReadOptions* read_options,
ROCKSDB_NAMESPACE::ColumnFamilyHandle* cf, rocksdb_input_slice_t* key,
rocksdb_pinnable_slice_t* value);
our input structure is
typedef struct rocksdb_input_slice {
const char* data;
size_t size;
} rocksdb_input_slice_t;
and our output structure is a pinnable slice (of which more later)
typedef struct rocksdb_pinnable_slice {
const char* data;
size_t size;
ROCKSDB_NAMESPACE::PinnableSlice* pinnable_slice;
bool is_pinned;
} rocksdb_pinnable_slice_t;
Java Side
We implement an FFIMethod class to advertise a java.lang.invoke.MethodHandle for each of our helper stubs
1
2
public static MethodHandle GetPinnable; // handle which refers to the rocksdb_ffi_get_pinnable method in C++
public static MethodHandle ResetPinnable; // handle which refers to the rocksdb_ffi_reset_pinnable method in C++
We also implement an FFILayout class to describe each of the passed structures (rocksdb_input_slice , rocksdb_pinnable_slice and rocksdb_output_slice) in Java terms
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public static class InputSlice {
static final GroupLayout Layout = ...
static final VarHandle Data = ...
static final VarHandle Size = ...
};
public static class PinnableSlice {
static final GroupLayout Layout = ...
static final VarHandle Data = ...
static final VarHandle Size = ...
static final VarHandle IsPinned = ...
};
public static class OutputSlice {
static final GroupLayout Layout = ...
static final VarHandle Data = ...
static final VarHandle Size = ...
};
The FFIDB class, which implements the public Java FFI API methods, makes use of FFIMethod and FFILayout to make the code for each individual method as idiomatic and efficient as possible. This class also contains java.lang.foreign.MemorySession and java.lang.foreign.SegmentAllocator objects which control the lifetime of native memory sessions and allow us to allocate lifetime-limited native memory which can be written and read by Java, and passed to native methods.
At the user level, we then present a method which wraps the details of use of FFIMethod and FFILayout to implement our single, core Java API get() method
1
2
3
public GetPinnableSlice getPinnableSlice(final ReadOptions readOptions,
final ColumnFamilyHandle columnFamilyHandle, final MemorySegment keySegment,
final GetParams getParams)
The flow of implementation of getPinnableSlice(), in common with any other core RocksDB FFI API method becomes:
- Allocate
MemorySegments forC++structures usingLayouts fromFFILayout - Write to the allocated structures using
VarHandles fromFFILayout - Invoke the native method using the
MethodHandlefromFFIMethodand addresses of instantiatedMemorySegments, or value types, as parameters - Read the call result and the output parameter(s), again using
VarHandles fromFFILayoutto perform the mapping.
For the getPinnableSlice() method, on successful return from an invocation of rocksdb_ffi_get(), the PinnableSlice object will contain the data and size fields of a pinnable slice (see below) containing the requested value. A MemorySegment referring to the native memory of the pinnable slice is then constructed, and used by the client to retrieve the value in whatever fashion they choose.
Pinnable Slices
RocksDB offers core (C++) API methods using the concept of a PinnableSlice to return fetched data values while reducing copies to a minimum. We take advantage of this to base our central get() method(s) on PinnableSlices. Methods mirroring the existing JNI-based API can then be implemented in pure Java by wrapping the core getPinnableSlice().
So we implement
1
2
3
4
public record GetPinnableSlice(Status.Code code, Optional<FFIPinnableSlice> pinnableSlice) {}
public GetPinnableSlice getPinnableSlice(
final ColumnFamilyHandle columnFamilyHandle, final byte[] key)
and we wrap that to provide
1
2
3
public record GetBytes(Status.Code code, byte[] value, long size) {}
public GetBytes get(final ColumnFamilyHandle columnFamilyHandle, final byte[] key)
Benchmark Results
We extended existing RocksDB Java JNI benchmarks with new benchmarks based on FFI. Full benchmark run on Ubuntu, including new benchmarks.
1
java --enable-preview --enable-native-access=ALL-UNNAMED -jar target/rocksdbjni-jmh-1.0-SNAPSHOT-benchmarks.jar -p keyCount=100000 -p keySize=128 -p valueSize=4096,65536 -p columnFamilyTestType="no_column_family" -rf csv org.rocksdb.jmh.GetBenchmarks
Discussion
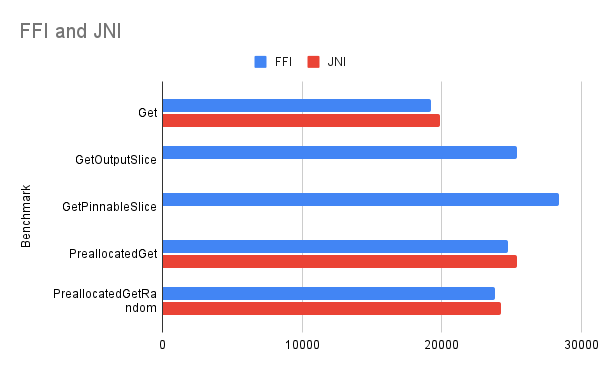
We have plotted the performance (more operations is better) of a selection of benchmarks,
1
q "select Benchmark,Score from ./plot/jmh-result-fixed.csv where \"Param: keyCount\"=100000 and \"Param: valueSize\"=65536 -d, -H
- JNI versions of benchmarks are previously implemented
jmhbenchmarks for measuring the performance of the current RocksDB Java interface. - FFI versions of benchmarks are equivalent benchmarks (as far as possible) implemented using the FFI mechanisms.
We can see that for all benchmarks which have equivalent FFI and JNI pairs, the JNI version is only very marginally faster. FFI has successfully optimized away most of the extra safety-checking of the new invocation mechanism.
Our initial implementation of FFI benchmarks lagged the JNI benchmarks quite significantly, but we have received extremely helpful support from Maurizio Cimadamore of the Panama Dev team, to help us optimize the performance of our FFI implementation. We consider that the small remaining performance gap is a feature of the remaining extra bounds checking of FFI.
For basic get() the result buffer is allocated by the method, so that there is a cost of allocation associated with each request.
ffiGetvsget- The JNI version is very marginally faster than FFI
For preallocated get() where the result buffer is supplied to the method, we avoid an allocation of a fresh result buffer on each call, and the test recycles its result buffers. Then the same small difference persists
- JNI is very marginally faster than FFI
preallocatedGet()is a lot faster than basicget()
We implemented some methods where the key for the get() is randomized, so that any ordering effects can be accounted for. The same differences persisted.
The FFI interface gives us a natural way to expose RocksDB’s pinnable slice mechanism. When we provide a benchmark which accesses the raw PinnableSlice API, as expected this is the fastest method of any; however we are not comparing like with like:
ffiGetPinnableSlice()returns a handle to the RocksDB memory containing the slice, and presents that as an FFIMemorySegment. No copying of the memory in the segment occurs.
As noted above, we implement the new FFI-based get() methods using the new FFI-based getPinnableSlice() method, and copying out the result. So the ffiGet and ffiPreallocatedGet benchmarks use this mechanism underneath.
In an effort to discover whether using the Java APIs to copy from the pinnable slice backed MemorySegment was a problem, we implemented a separate ffiGetOutputSlice() benchmark which copies the result into a (Java allocated native memory) segment at the C++ side.
ffiGetOutputSlice()is faster thanffiPreallocatedGet()and is in fact at least as fast aspreallocatedGet(), which is an almost exact analogue in the JNI world.
So it appears that we can build an FFI-based API with equal performance to the JNI-based one.
Thinking about the (very small, but probably statistically significant) difference between our ffiGetPinnableSlice()-based FFI calls and the JNI-based calls, it is reasonable to expect that some of the cost is the extra FFI call to C++ to release the pinned slice as a separate operation. A null FFI method call is extremely fast, but it does take some time.
- We would recommend looking again the performance of the FFI-based implementation when Panama is release post-Preview in Java 21. It seems that at least with Java 20 the performance is of our FFI benchmarks is not significantly different from that of the Java 19 version.
Copies versus Calls
The second method call over the FFI boundary to release a pinnable slice has a cost. We compared the ffiGetOutputSlice() and ffiGetPinnableSlice() benchmarks in order to examine this cost. We ran it with a fixed ky size (128 bytes); the key size is likely to be pretty much irrelevant anyway; we varied the value size read from 16 bytes to 16k, and we found a crossover point between 1k and 4k for performance:
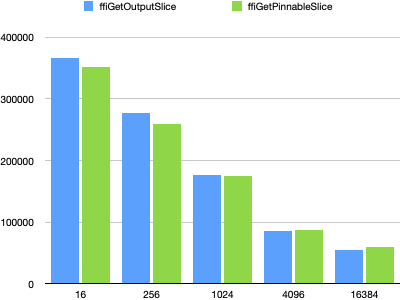
ffiGetOutputSlice()is faster when values read are 1k in size or smaller. The cost of an extra copy in the C++ side from the pinnable slice buffer into the supplied buffer allocated by Java Foreign Memory API is less than the cost of the extra call to release a pinnable slice.ffiGetPinnableSlice()is faster when values read are 4k in size, or larger. Consistent with intuition, the advantage grows with larger read values.
The way that the RocksDB API is constructed means that of the 2 methods compared, ffiGetOutputSlice() will always make exactly 1 more copy than ffiGetPinnableSlice(). The underlying RocksDB C++ API will always copy into its own temporary buffer if it decides that it cannot pin an internal buffer, and that will be returned as the pinnable slice. There is a potential optimization where the temporary buffer could be replaced by an output buffer, such as that supplied by ffiGetOutputSlice(); in practice that is a hard fix to hack in. Its effectiveness depends on how often RocksDB fails to pin an internal buffer.
A solution which either filled a buffer or returned a pinnable slice would give us the best of both worlds.
Other Conclusions
Build Processing
-
It is easier to implement an interface using FFI than JNI. No intermediate build processing or code generation steps were needed to implement this protoype.
-
For a production version, we would urge using
jextractto automate the process of generating Java API methods from the set of supporting stubs we generate.
Safety
- The use of
jextractwill give a similar level of type security to the use of JNI, when crossing the language boundary. But we do not believe FFI is significantly more type-safe than JNI for method invocation. Neither is it less safe, though.
Native Memory
Panama’s Foreign-Memory Access API appears to us to be the most significant part of the whole project. At the Java side of RocksDB it gives us a clean mechanism (a MemorySegment) for holding RocksDB data (e.g. as from the result of a get()) call pending its forwarding to client code or network buffers.
We have taken advantage of this mechanism to provide the core FFIDB.getPinnableSlice() method in our Panama-based API. The rest of our prototype get() API, duplicating the existing JNI-based API, is then a Pure Java library on top of FFIDB.getPinnableSlice() and FFIPinnableSlice.reset().
The common standard for foreign memory opens up the possibility of efficient interoperation between RocksDB and Java clients (e.g. Kafka). We think that this is really the key to higher performing, more integrated Java-based systems:
- This could result in data never being copied into Java memory, or a significant reduction in copies, as native
MemorySegments are handed off between co-operating Java clients of fundamentally native APIs. This extra potential performance can be extremely useful when 2 or more clients are interoperating; we still need to provide a simplest possible API wrapping these calls (like our prototypeget()), which operates at a similar level to the current Java API. - Some thought should be applied to how this architecture would interact with the cache layer(s) in RocksDB, and whether it can be accommodated within the present RocksDB architecture. How long can 3rd-party applications pin pages in the RocksDB cache without disrupting RocksDB normal behaviour (e.g. compaction) ?
Summary
- Panama/FFI (in Preview) is a highly capable technology for (re)building the RocksDB Java API, although the supported language level of RocksDB and the planned release schedule for Panama mean that it could not replace JNI in production for some time to come.
- Panama/FFI would seem to offer comparable performance to JNI; there is no strong performance argument for a re-implementation of a standalone RocksDB Java API. But the opportunity to provide a natural pinnable slice-based API gives a lot of flexibility; not least because an efficient API could be built mostly in Java with only a small underlying layer implementing the pinnable slice interface.
- Panama/FFI can remove some boilerplate (native method declarations) and allow Java programs to access
Clibraries without stub code, but calling aC++-based library still requiresCstubs; a possible approach would be to use the RocksDBCAPI as the basis for a rebuilt Java API. This would allow us to remove all the existing JNI boilerplate, and concentrate support effort on theCAPI. An alternative approach would be to build a robust API based on Reference Counting, but using FFI. - Panama/FFI really shines as a foreign memory standard for a Java API that can allow efficient interoperation between RocksDB Java clients and other (Java and native) components of a system. Foreign Memory gives us a model for how to efficiently return data from RocksDB; as pinnable slices with their contents presented in
MemorySegments. If we focus on designing an API for native interoperability we think this can be highly productive in opening RocksDB to new uses and opportunities in future.
Appendix
Code and Data
The Experimental Pull Request contains the source code implemented, together with further data plots and the source CSV files for all data plots.
Running
This is an example run; the jmh parameters (after -p) can be changed to measure performance with varying key counts, and key and value sizes.
1
java --enable-preview --enable-native-access=ALL-UNNAMED -jar target/rocksdbjni-jmh-1.0-SNAPSHOT-benchmarks.jar -p keyCount=100000 -p keySize=128 -p valueSize=4096,65536 -p columnFamilyTestType="no_column_family" -rf csv org.rocksdb.jmh.GetBenchmarks -wi 1 -to 1m -i 1
Processing
Use q to select the csv output for analysis and graphing.
- Note that we edited the column headings for easier processing
1
q "select Benchmark,Score,Error from ./plot/jmh-result.csv where keyCount=100000 and valueSize=65536" -d, -H -C readwrite
Java 19 installation
We followed the instructions to install Azul. Then select the correct instance of java locally:
1
2
sudo update-alternatives --config java
sudo update-alternatives --config javac
And set JAVA_HOME appropriately. In my case, sudo update-alternatives --config java listed a few JVMs thus:
1
2
3
4
0 /usr/lib/jvm/bellsoft-java8-full-amd64/bin/java 20803123 auto mode
1 /usr/lib/jvm/bellsoft-java8-full-amd64/bin/java 20803123 manual mode
2 /usr/lib/jvm/java-11-openjdk-amd64/bin/java 1111 manual mode
* 3 /usr/lib/jvm/zulu19/bin/java 2193001 manual mode
For our environment, we set this:
1
export JAVA_HOME=/usr/lib/jvm/zulu19
The default version of Maven avaiable on the Ubuntu package repositories (3.6.3) is incompatible with Java 19. You will need to install a later Maven, and use it. I used 3.8.7 successfully.
Java 20, 21, 22 and subsequent versions
The FFI version we used was a preview in Java 19, and the interface has changed through to Java 22, where it has been finalized. Future work with this prototype will need to update the code to use the changed interface.